
High-Availability (HA) tries to keep VMs running, even when there are hardware failures in the resource pool, when the admin is not present. Without HA the following may happen:
With HA the following will happen:
HA is designed to handle an emergency and allow the admin time to fix failures properly.
The following diagram shows an HA-enabled pool, before and after a network link between two hosts fails.
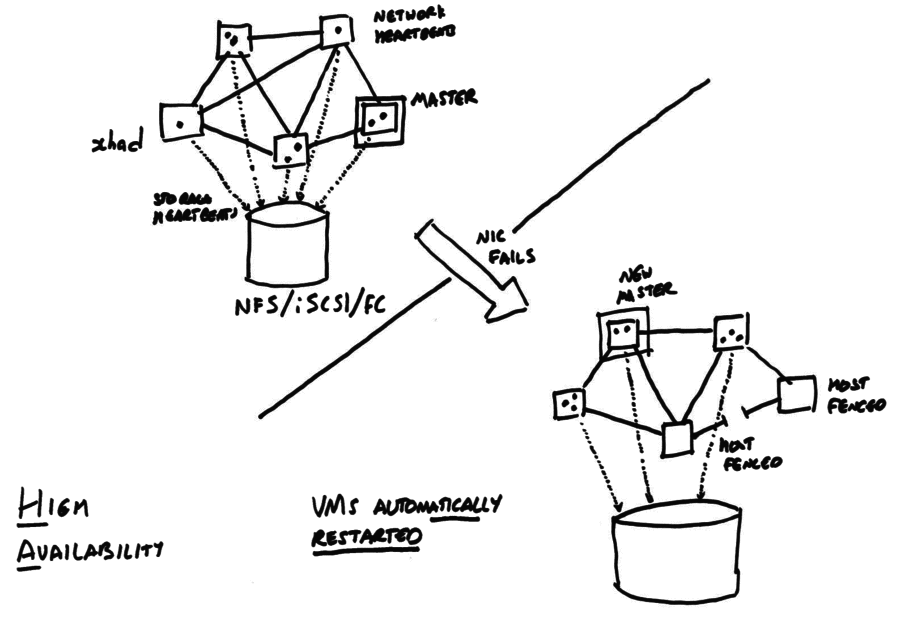
When HA is enabled, all hosts in the pool
HA is designed to recover as much as possible of the pool after a single failure i.e. it removes single points of failure. When some subset of the pool suffers a failure then the remaining pool members
After HA has recovered a pool, it is important that the original failure is addressed because the remaining pool members may not be able to cope with any more failures.
HA must never violate the following safety rules:
However to be useful HA must:
The implementation difficulty arises when trying to be both useful and safe at the same time.
We use the following terminology:
resident_on there. When a Host b
leaves the liveset as seen by Host a it is safe for Host a to assume
that Host b has been fenced and to take recovery actions (e.g. restarting
VMs), without violating either of the safety-rules.shared=true; and which has a
PBD connecting it to every enabled Host in the Pool; and where each of
these PBDs has field currently_attached set to true. A VM whose disks
are in a properly shared SR could be restarted on any enabled Host,
memory and network permitting.PIF connecting it to
every enabled Host in the Pool; and where each of these PIFs has
field currently_attached set to true. A VM whose VIFs connect to
properly shared Networks could be restarted on any enabled Host,
memory and storage permitting.ha_always_run set to false
and will never be restarted automatically on failure
or have reconfiguration actions blocked by the HA overcommit protection.ha_always_run set to true and
ha_restart_priority set to best-effort.
A best-effort VM will only be restarted if (i) the failure is directly
observed; and (ii) capacity exists for an immediate restart.
No more than one restart attempt will ever be made.ha_always_run set to true and
field ha_restart_priority not set to `best-effort.xhad daemon.We assume:
--force flag then the additional
constraints will not be noticed by the VM failover planner resulting in
runtime failures while trying to execute the failover plans.The implementation is split across the following components:
To avoid a “split-brain”, the cluster membership daemon must “fence” (i.e. isolate) nodes when they are not part of the cluster. In general there are 2 approaches:
xhad is the cluster membership daemon: it exchanges heartbeats with the other nodes to determine which nodes are still in the cluster (the “live set”) and which nodes have definitely failed (through watchdog fencing). When a host has definitely failed, xapi will unlock all the disks and restart the VMs according to the HA policy.
Since Xapi is a critical part of the system, the xhad also acts as a Xapi watchdog. It polls Xapi every few seconds and checks if Xapi can respond. If Xapi seems to have failed then xhad will restart it. If restarts continue to fail then xhad will consider the host to have failed and self-fence.
xhad is configured via a simple config file written on each host in
/etc/xensource/xhad.conf. The file must be identical on each host
in the cluster. To make changes to the file, HA must be disabled and then
re-enabled afterwards. Note it may not be possible to re-enable HA depending
on the configuration change (e.g. if a host has been added but that host has
a broken network configuration then this will block HA enable).
The xhad.conf file is written in XML and contains
The following is an example xhad.conf file:
<?xml version="1.0" encoding="utf-8"?>
<xhad-config version="1.0">
<!--pool-wide configuration-->
<common-config>
<GenerationUUID>xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx</GenerationUUID>
<UDPport>694</UDPport>
<!--for each host, specify host UUID, and IP address-->
<host>
<HostID>xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx</HostID>
<IPaddress>xxx.xxx.xxx.xx1</IPaddress>
</host>
<host>
<HostID>xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx</HostID>
<IPaddress>xxx.xxx.xxx.xx2</IPaddress>
</host>
<host>
<HostID>xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx</HostID>
<IPaddress>xxx.xxx.xxx.xx3</IPaddress>
</host>
<!--optional parameters [sec] -->
<parameters>
<HeartbeatInterval>4</HeartbeatInterval>
<HeartbeatTimeout>30</HeartbeatTimeout>
<StateFileInterval>4</StateFileInterval>
<StateFileTimeout>30</StateFileTimeout>
<HeartbeatWatchdogTimeout>30</HeartbeatWatchdogTimeout>
<StateFileWatchdogTimeout>45</StateFileWatchdogTimeout>
<BootJoinTimeout>90</BootJoinTimeout>
<EnableJoinTimeout>90</EnableJoinTimeout>
<XapiHealthCheckInterval>60</XapiHealthCheckInterval>
<XapiHealthCheckTimeout>10</XapiHealthCheckTimeout>
<XapiRestartAttempts>1</XapiRestartAttempts>
<XapiRestartTimeout>30</XapiRestartTimeout>
<XapiLicenseCheckTimeout>30</XapiLicenseCheckTimeout>
</parameters>
</common-config>
<!--local host configuration-->
<local-config>
<localhost>
<HostID>xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx2</HostID>
<HeartbeatInterface> xapi1</HeartbeatInterface>
<HeartbeatPhysicalInterface>bond0</HeartbeatPhysicalInterface>
<StateFile>/dev/statefiledevicename</StateFile>
</localhost>
</local-config>
</xhad-config>
The fields have the following meaning:
T.
T must be bigger than 10; we would normally use 60s.T.2 <= t <= 6, derived from the user-supplied
HA timeout via t = (T + 10) / 10T.T+15.T+60.T+60.In addition to the config file, Xhad exposes a simple control API which is exposed as scripts:
ha_set_pool_state (Init | Invalid): sets the global pool state to “Init” (before starting
HA) or “Invalid” (causing all other daemons who can see the statefile to
shutdown)ha_start_daemon: if the pool state is “Init” then the daemon will
attempt to contact other daemons and enable HA. If the pool state is
“Active” then the host will attempt to join the existing liveset.ha_query_liveset: returns the current state of the cluster.ha_propose_master: returns whether the current node has been
elected pool master.ha_stop_daemon: shuts down the xhad on the local host. Note this
will not disarm the Xen watchdog by itself.ha_disarm_fencing: disables fencing on the local host.ha_set_excluded: when a host is being shutdown cleanly, record the
fact that the VMs have all been shutdown so that this host can be ignored
in future cluster membership calculations.Xhad continuously monitors whether the host should remain alive, or if it should self-fence. There are two “survival rules” which will keep a host alive; if neither rule applies (or if xhad crashes or deadlocks) then the host will fence. The rules are:
where the “best” partition is the largest one if that is unique, or if there are multiple partitions of the same size then the one containing the lowest host uuid is considered best.
The first survival rule is the “normal” case. The second rule exists only to prevent the storage from becoming a single point of failure: all hosts can remain alive until the storage is repaired. Note that if a host has failed and has not yet been repaired, then the storage becomes a single point of failure for the degraded pool. HA removes single point of failures, but multiple failures can still cause problems. It is important to fix failures properly after HA has worked around them.
Xapi is responsible for
xhad heartbeating daemonThe HA policy APIs include
The HA policy settings are stored in the Pool database which is written (synchronously) to a VDI in the same SR that’s being used for heartbeating. This ensures that the database can be recovered after a host fails and the VMs are recovered.
Xapi stores 2 settings in its local database:
Xhad during
host startup and wait to join the liveset.The regular disk APIs for creating, destroying, attaching, detaching (etc)
disks need the SRmaster (usually but not always the Pool master) to be
online to allow the disks to be locked. The SRmaster cannot be brought
online until the host has joined the liveset. Therefore we have a
cyclic dependency: joining the liveset needs the statefile disk to be attached
but attaching a disk requires being a member of the liveset already.
The dependency is broken by adding an explicit “unlocked” attach storage
API called VDI_ATTACH_FROM_CONFIG. Xapi uses the VDI_GENERATE_CONFIG API
during the HA enable operation and stores away the result. When the system
boots the VDI_ATTACH_FROM_CONFIG is able to attach the disk without the
SRmaster.
The Host.enabled flag is used to mean, “this host is ready to start VMs and
should be included in failure planning”.
The VM restart planner assumes for simplicity that all protected VMs can
be started anywhere; therefore all involved networks and storage must be
properly shared.
If a host with an unplugged PBD were to become enabled then the corresponding
SR would cease to be properly shared, all the VMs would cease to be
agile and the VM restart logic would fail.
To ensure the VM restart logic always works, great care is taken to make sure that Hosts may only become enabled when their networks and storage are properly configured. This is achieved by:
xapi has just restarted) it calls
consider_enabling_host}When HA is enabled and all hosts are running normally then each calls
ha_query_liveset every 10s.
Slaves check to see if the host they believe is the master is alive and has
the master lock. If another node has become master then the slave will
rewrite its pool.conf and restart. If no node is the master then the
slave will call
on_master_failure,
proposing itself and, if it is rejected,
checking the liveset to see which node acquired the lock.
The master monitors the liveset and updates the Host_metrics.live flag
of every host to reflect the liveset value. For every host which is not in
the liveset (i.e. has fenced) it enumerates all resident VMs and marks them
as Halted. For each protected VM which is not running, the master computes
a VM restart plan and attempts to execute it. If the plan fails then a
best-effort VM.start call is attempted. Finally an alert is generated if
the VM could not be restarted.
Note that XenAPI heartbeats are still sent when HA is enabled, even though
they are not used to drive the values of the Host_metrics.live field.
Note further that, when a host is being shutdown, the host is immediately
marked as dead and its host reference is added to a list used to prevent the
Host_metrics.live being accidentally reset back to live again by the
asynchronous liveset query. The Host reference is removed from the list when
the host restarts and calls Pool.hello.
The VM failover planning code is sub-divided into two pieces, stored in separate files:
The input to the binpacking algorithms are configuration values which represent an abstract view of the Pool:
type ('a, 'b) configuration = {
hosts: ('a * int64) list; (** a list of live hosts and free memory *)
vms: ('b * int64) list; (** a list of VMs and their memory requirements *)
placement: ('b * 'a) list; (** current VM locations *)
total_hosts: int; (** total number of hosts in the pool 'n' *)
num_failures: int; (** number of failures to tolerate 'r' *)
}
Note that:
placement has already been
substracted from the total memory of the hosts; it doesn’t need to be
subtracted again.total_hosts) is a constant for
any particular invocation of HA.num_failures) is the user-settable
value from the XenAPI Pool.ha_host_failures_to_tolerate.There are two algorithms which satisfy the interface:
sig
plan_always_possible: ('a, 'b) configuration -> bool;
get_specific_plan: ('a, 'b) configuration -> 'b list -> ('b * 'a) list
end
The function get_specific_plan takes a configuration and a list of Hosts
which have failed. It returns a VM restart plan represented as a VM to Host
association list. This is the function called by the
background HA VM restart thread on the master.
The function plan_always_possible returns true if every sequence of Host
failures of length
num_failures (irrespective of whether all hosts failed at once, or in
multiple separate episodes)
would result in calls to get_specific_plan which would allow all protected
VMs to be restarted.
This function is heavily used by the overcommit protection logic as well as code in XenCenter which aims to
maximise failover capacity using the counterfactual reasoning APIs:
Pool.ha_compute_max_host_failures_to_tolerate
Pool.ha_compute_hypothetical_max_host_failures_to_tolerate
There are two binpacking algorithms: the more detailed but expensive
algorithmm is used for smaller/less
complicated pool configurations while the less detailed, cheaper algorithm
is used for the rest. The
choice between algorithms is based only on total_hosts (n) and
num_failures (r).
Note that the choice of algorithm will only change if the number of Pool
hosts is varied (requiring HA to be disabled and then enabled) or if the
user requests a new num_failures target to plan for.
The expensive algorithm uses an exchaustive search with a “biggest-fit-decreasing” strategy that takes the biggest VMs first and allocates them to the biggest remaining Host. The implementation keeps the VMs and Hosts as sorted lists throughout. There are a number of transformations to the input configuration which are guaranteed to preserve the existence of a VM to host allocation (even if the actual allocation is different). These transformations which are safe are:
The cheaper algorithm is used for larger Pools where the state space to search is too large. It uses the same “biggest-fit-decreasing” strategy with the following simplifying approximations:
An informal argument that these approximations are safe is as follows: if the maximum number of VMs fail, each of which is size of the largest and we can find a restart plan using only the smaller hosts then any real failure:
Therefore we can take this almost-certainly-worse-than-worst-case failure plan and:
Note that this strategy will perform best when each host has the same number of VMs on it and when all VMs are approximately the same size. If one very big VM exists and a lot of smaller VMs then it will probably fail to find a plan. It is more tolerant of differing amounts of free host memory.
Overcommit protection blocks operations which would prevent the Pool being able to restart protected VMs after host failure. The Pool may become unable to restart protected VMs in two general ways: (i) by running out of resource i.e. host memory; and (ii) by altering host configuration in such a way that VMs cannot be started (or the planner thinks that VMs cannot be started).
API calls which would change the amount of host memory currently in use
(VM.start, VM.resume, VM.migrate etc)
have been modified to call the planning functions supplying special
“configuration change” parameters.
Configuration change values represent the proposed operation and have type
type configuration_change = {
(** existing VMs which are leaving *)
old_vms_leaving: (API.ref_host * (API.ref_VM * API.vM_t)) list;
(** existing VMs which are arriving *)
old_vms_arriving: (API.ref_host * (API.ref_VM * API.vM_t)) list;
(** hosts to pretend to disable *)
hosts_to_disable: API.ref_host list;
(** new number of failures to consider *)
num_failures: int option;
(** new VMs to restart *)
new_vms_to_protect: API.ref_VM list;
}
A VM migration will be represented by saying the VM is “leaving” one host and “arriving” at another. A VM start or resume will be represented by saying the VM is “arriving” on a host.
Note that no attempt is made to integrate the overcommit protection with the
general VM.start host chooser as this would be quite expensive.
Note that the overcommit protection calls are written as asserts called
within the message forwarder in the master, holding the main forwarding lock.
API calls which would change the system configuration in such a way as to prevent the HA restart planner being able to guarantee to restart protected VMs are also blocked. These calls include:
VBD.create: where the disk is not in a properly shared SRVBD.insert: where the CDROM is local to a hostVIF.create: where the network is not properly sharedPIF.unplug: when the network would cease to be properly sharedPBD.unplug: when the storage would cease to be properly sharedHost.enable: when some network or storage would cease to be
properly shared (e.g. if this host had a broken storage configuration)The Xen hypervisor has per-domain watchdog counters which, when enabled, decrement as time passes and can be reset from a hypercall from the domain. If the domain fails to make the hypercall and the timer reaches zero then the domain is immediately shutdown with reason reboot. We configure Xen to reboot the host when domain 0 enters this state.
Before HA can be enabled the admin must take care to configure the environment properly. In particular:
The XenAPI client can request a specific shared SR to be used for
storage heartbeats, otherwise Xapi will use the Pool’s default SR.
Xapi will use VDI_GENERATE_CONFIG to ensure the disk will be attached
automatically on system boot before the liveset has been joined.
Note that extra effort is made to re-use any existing heartbeat VDIS so that
The Xapi-to-Xapi communication looks as follows:

The Xapi Pool master calls Host.ha_join_liveset on all hosts in the
pool simultaneously. Each host
runs the ha_start_daemon script
which starts Xhad. Each Xhad starts exchanging heartbeats over the network
and storage defined in the xhad.conf.

The Xhad instances exchange heartbeats and decide which hosts are in the “liveset” and which have been fenced.
After joining the liveset, each host clears the “excluded” flag which would have been set if the host had been shutdown cleanly before – this is only needed when a host is shutdown cleanly and then restarted.
Xapi periodically queries the state of xhad via the ha_query_liveset
command. The state will be Starting until the liveset is fully
formed at which point the state will be Online.
When the ha_start_daemon script returns then Xapi will decide
whether to stand for master election or not. Initially when HA is being
enabled and there is a master already, this node will be expected to
stand unopposed. Later when HA notices that the master host has been
fenced, all remaining hosts will stand for election and one of them will
be chosen.

When a host is to be shutdown cleanly, it can be safely “excluded” from the pool such that a future failure of the storage heartbeat will not cause all pool hosts to self-fence (see survival rule 2 above). When a host is “excluded” all other hosts know that the host does not consider itself a master and has no resources locked i.e. no VMs are running on it. An excluded host will never allow itself to form part of a “split brain”.
Once a host has given up its master role and shutdown any VMs, it is safe
to disable fencing with ha_disarm_fencing and stop xhad with
ha_stop_daemon. Once the daemon has been stopped the “excluded”
bit can be set in the statefile via ha_set_excluded and the
host safely rebooted.
When a host restarts after a failure Xapi notices that ha_armed is set in the local database. Xapi
attach-static-vdis script to attach the statefile and
database VDIs. This can fail if the storage is inaccessible; Xapi will
retry until it succeeds.In the special case where Xhad fails to access the statefile and the host used to be a slave then Xapi will try to contact the previous master and find out
If Xapi can confirm that HA was disabled then it will disarm itself and join the new master. Otherwise it will keep waiting for the statefile to recover.
In the special case where the statefile has been destroyed and cannot be recovered, there is an emergency HA disable API the admin can use to assert that HA really has been disabled, and it’s not simply a connectivity problem. Obviously this API should only be used if the admin is totally sure that HA has been disabled.
There are 2 methods of disabling HA: one for the “normal” case when the statefile is available; and the other for the “emergency” case when the statefile has failed and can’t be recovered.

HA can be shutdown cleanly when the statefile is working i.e. when hosts
are alive because of survival rule 1. First the master Xapi tells the local
Xhad to mark the pool state as “invalid” using ha_set_pool_state.
Every xhad instance will notice this state change the next time it performs
a storage heartbeat. The Xhad instances will shutdown and Xapi will notice
that HA has been disabled the next time it attempts to query the liveset.
If a host loses access to the statefile (or if none of the hosts have access to the statefile) then HA can be disabled uncleanly.
The Xapi master first calls Host.ha_disable_failover_actions on each host
which sets ha_disable_failover_decisions in the lcoal database. This
prevents the node rebooting, gaining statefile access, acquiring the
master lock and restarting VMs when other hosts have disabled their
fencing (i.e. a “split brain”).

Once the master is sure that no host will suddenly start recovering VMs
it is safe to call Host.ha_disarm_fencing which runs the script
ha_disarm_fencing and then shuts down the Xhad with ha_stop_daemon.
We assume that adding a host to the pool is an operation the admin will perform manually, so it is acceptable to disable HA for the duration and to re-enable it afterwards. If a failure happens during this operation then the admin will take care of it by hand.