Subsections of The Toolstack
Responsibilities
The XAPI Toolstack forms the main control plane of a pool of XenServer hosts. It allows the administrator to:
- Configure the hardware resources of XenServer hosts: storage, networking, graphics, memory.
- Create, configure and destroy VMs and their virtual resources.
- Control the lifecycle of VMs.
- Monitor the status of hosts, VMs and related resources.
To this, the Toolstack:
- Exposes an API that can be accessed by external clients over HTTP(s).
- Exposes a CLI.
- Ensures that physical resources are configured when needed, and VMs receive the resources they require.
- Implements various features to help the administrator manage their systems.
- Monitors running VMs.
- Records metrics about physical and virtual resources.
High-level architecture
The XAPI Toolstack manages a cluster of hosts, network switches and storage on behalf of clients such as XenCenter and Xen Orchestra.
The most fundamental concept is of a Resource pool: the whole cluster managed as a single entity. The following diagram shows a cluster of hosts running xapi, all sharing some storage:
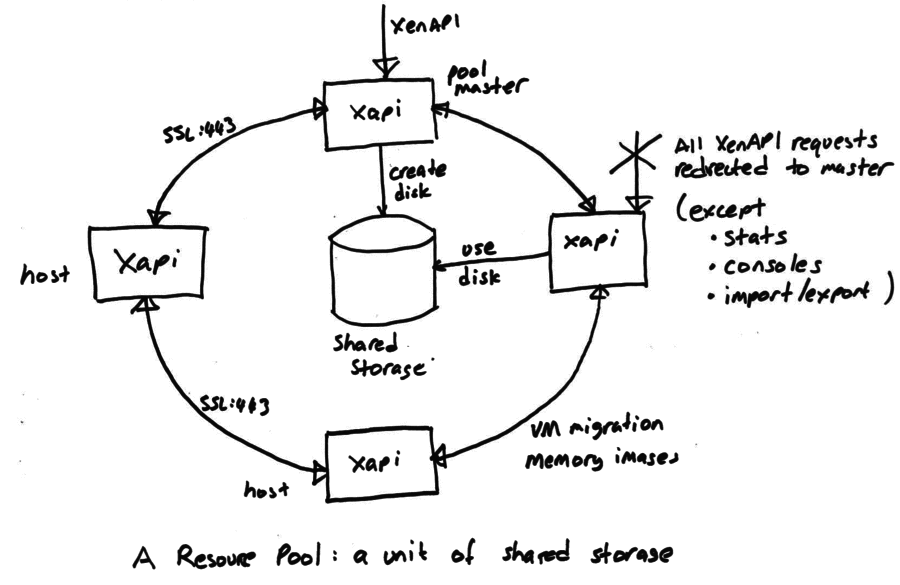
At any time, at most one host is known as the pool coordinator (formerly known as “master”) and is responsible for coordination and locking resources within the pool. When a pool is first created a coordinator host is chosen. The coordinator role can be transferred
- on user request in an orderly fashion (
xe pool-designate-new-master) - on user request in an emergency (
xe pool-emergency-transition-to-master) - automatically if HA is enabled on the cluster.
All hosts expose an HTTP, XML-RPC and JSON-RPC interface running on port 80 and with TLS on port 443, but control operations will only be processed on the coordinator host. Attempts to send a control operation to another host will result in a XenAPI redirect error message. For efficiency the following operations are permitted on non-coordinator hosts:
- querying performance counters (and their history)
- connecting to VNC consoles
- import/export (particularly when disks are on local storage)
Since the coordinator host acts as coordinator and lock manager, the other hosts will often talk to the coordinator. Non-coordinator hosts will also talk to each other (over the same HTTP and RPC channels) to
- transfer VM memory images (VM migration)
- mirror disks (storage migration)
Note that some types of shared storage (in particular all those using vhd) require coordination for disk GC and coalesce. This coordination is currently done by xapi and hence it is not possible to share this kind of storage between resource pools.
The following diagram shows the software running on a single host. Note that all hosts run the same software (although not necessarily the same version, if we are in the middle of a rolling update).
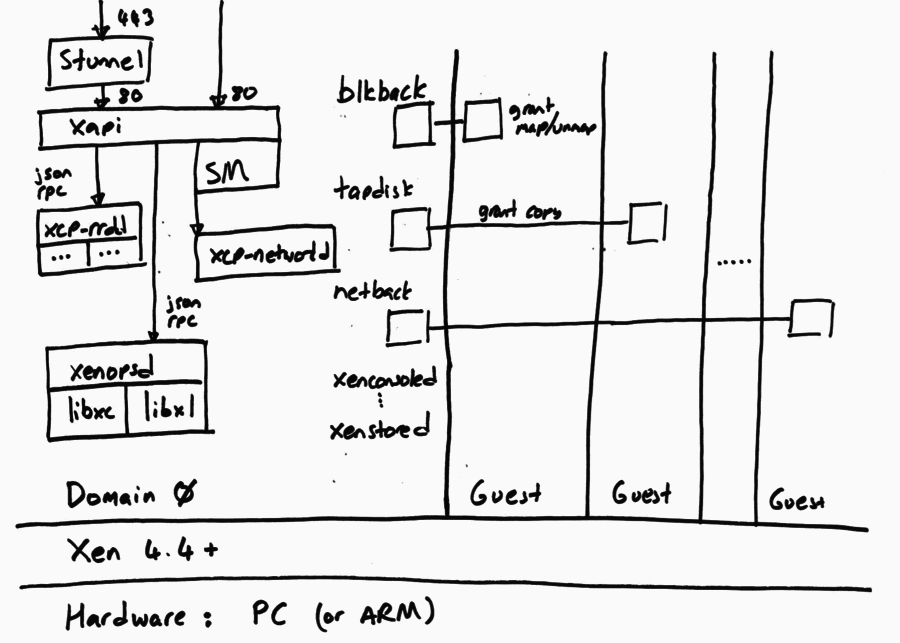
The XAPI Toolstack expects the host to be running Xen on x86. The Xen hypervisor partitions the host into Domains, some of which can have privileged hardware access, and the rest are unprivileged guests. The XAPI Toolstack normally runs all of its components in the privileged initial domain, Domain 0, also known as “the control domain”. However there is experimental code which supports “driver domains” allowing storage and networking drivers to be isolated in their own domains.
Subsections of High-level architecture
Environment
The Toolstack runs in an environment on a server (host) that has:
- Physical hardware.
- The Xen hypervisor.
- The control domain (domain 0): the privileged domain that the Toolstack runs in.
- Other, mostly unprivileged domains, usually for guests (VMs).
The Toolstack relies on various bits of software inside the control domain, and directly communicates with most of these:
- Linux kernel including drivers for hardware and Xen paravirtualised devices (e.g.
netbackandblkback).- Interacts through
/sysand/proc, udev scripts, xenstore, …
- Interacts through
- CentOS distribution including userspace tools and libraries.
- systemd, networking tools, …
- Xen-specific libraries, especially
libxenctrl(a.k.a.libxc) xenstored: a key-value pair configuration database- Accessible from all domains on a host, which makes it useful for inter-domain communication.
- The control domain has access to the entire xenstore database, while other domains only see sub-trees that are specific to that domain.
- Used for connecting VM disks and network interfaces, and other VM configuration options.
- Used for VM status reporting, e.g. the capabilities of the PV drivers (if installed), the IP address, etc.
- SM: Storage Manager plugins which connect xapi’s internal storage interfaces to the control APIs of external storage systems.
stunnel: a daemon which decodes TLS and forwards traffic to xapi (and the other way around).- Open vSwitch (OVS): a virtual network switch, used to connect VMs to network interfaces. The OVS offers several networking features that xapi takes advantage of.
- QEMU: emulation of various bits of hardware
- DEMU: emulation of Nvidia vGPUs
xenguestemu-managerpvsproxyxenconsoled: allows access to guest consoles. This is common to all Xen hosts.
The Toolstack also interacts with software that runs inside the guests:
- PV drivers
- The guest agent
Daemons
The Toolstack consists of a set of co-operating daemons:
- xapi
- manages clusters of hosts, co-ordinating access to shared storage and networking.
- xenopsd
- a low-level “domain manager” which takes care of creating, suspending, resuming, migrating, rebooting domains by interacting with Xen via libxc and libxl.
- xcp-rrdd
- a performance counter monitoring daemon which aggregates “datasources” defined
via a plugin API and records history for each. There are various rrdd-plugin daemons:
- xcp-rrdd-gpumon
- xcp-rrdd-iostat
- xcp-rrdd-squeezed
- xcp-rrdd-xenpm
- xcp-rrdd-dcmi
- xcp-rrdd-netdev
- xcp-rrdd-cpu
- xcp-networkd
- a host network manager which takes care of configuring interfaces, bridges and OpenVSwitch instances
- squeezed
- a daemon in charge of VM memory management
- xapi-storage-script
- for storage manipulation over SMAPIv3
- message-switch
- exchanges messages between the daemons on a host
- xapi-guard
- forwards uefi and vtpm persistence calls from domains to xapi
- v6d
- controls which features are enabled.
- forkexecd
- a helper daemon that assists the above daemons with executing binaries and scripts
- xhad
- The High-Availability daemon
- perfmon
- a daemon which monitors performance counters and sends “alerts” if values exceed some pre-defined threshold
- mpathalert
- a daemon which monitors “storage paths” and sends “alerts” if paths fail and need repair
- wsproxy
- handles access to VM consoles
Interfaces
Communication between the Toolstack daemon is built upon libraries from a component called xapi-idl.
- Abstracts communication between daemons over the message-switch using JSON/RPC.
- Contains the definition of the interfaces exposed by the daemons (except xapi).
Features
Subsections of Features
Disaster Recovery
The HA feature will restart VMs after hosts have failed, but what happens if a whole site (e.g. datacenter) is lost? A disaster recovery configuration is shown in the following diagram:
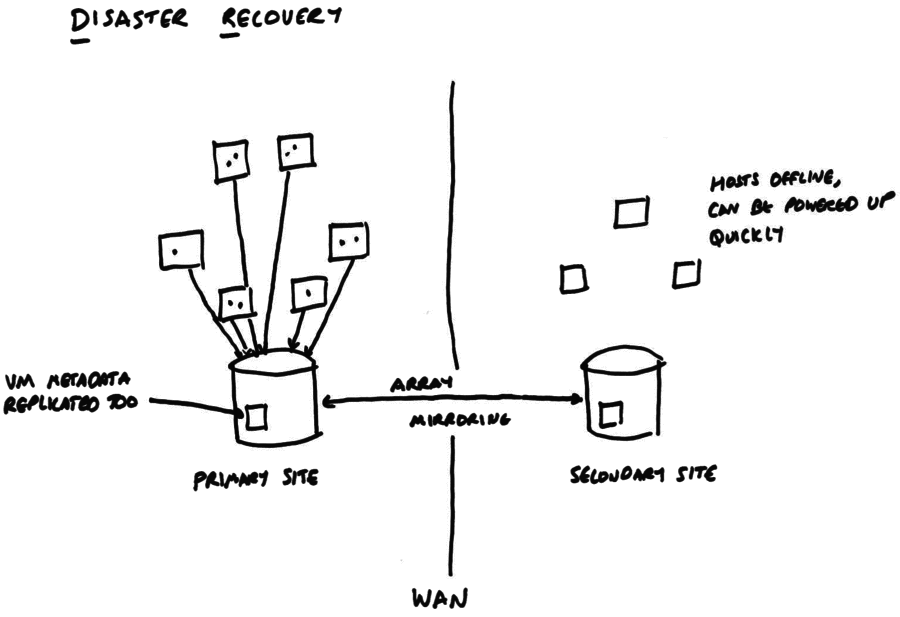
We rely on the storage array’s built-in mirroring to replicate (synchronously or asynchronously: the admin’s choice) between the primary and the secondary site. When DR is enabled the VM disk data and VM metadata are written to the storage server and mirrored. The secondary site contains the other side of the data mirror and a set of hosts, which may be powered off.
In normal operation, the DR feature allows a “dry-run” recovery where a host on the secondary site checks that it can indeed see all the VM disk data and metadata. This should be done regularly, so that admins are familiar with the process.
After a disaster, the admin breaks the mirror on the secondary site and triggers a remote power-on of the offline hosts (either using an out-of-band tool or the built-in host power-on feature of xapi). The pool master on the secondary site can connect to the storage and extract all the VM metadata. Finally the VMs can all be restarted.
When the primary site is fully recovered, the mirror can be re-synchronised and the VMs can be moved back.
Event handling in the Control Plane - Xapi, Xenopsd and Xenstore
Introduction
Xapi, xenopsd and xenstore use a number of different events to obtain indications that some state changed in dom0 or in the guests. The events are used as an efficient alternative to polling all these states periodically.
- xenstore provides a very configurable approach in which each and any key can be watched individually by a xenstore client. Once the value of a watched key changes, xenstore will indicate to the client that the value for that key has changed. An ocaml xenstore client library provides a way for ocaml programs such as xenopsd, message-cli and rrdd to provide high-level ocaml callback functions to watch specific key. It’s very common, for instance, for xenopsd to watch specific keys in the xenstore keyspace of a guest and then after receiving events for some or all of them, read other keys or subkeys in xenstored to update its internal state mirroring the state of guests and its devices (for instance, if the guest has pv drivers and specific frontend devices have established connections with the backend devices in dom0).
- xapi also provides a very configurable event mechanism in which the xenapi can be used to provide events whenever a xapi object (for instance, a VM, a VBD etc) changes state. This event mechanism is very reliable and is extensively used by XenCenter to provide real-time update on the XenCenter GUI.
- xenopsd provides a somewhat less configurable event mechanism, where it always provides signals for all objects (VBDs, VMs etc) whose state changed (so it’s not possible to select a subset of objects to watch for as in xenstore or in xapi). It’s up to the xenopsd client (eg. xapi) to receive these events and then filter out or act on each received signal by calling back xenopsd and asking it information for the specific signalled object. The main use in xapi for the xenopsd signals is to update xapi’s database of the current state of each object controlled by xenopsd (VBDs, VMs etc).
Given a choice between polling states and receiving events when the state change, we should in general opt for receiving events in the code in order to avoid adding bottlenecks in dom0 that will prevent the scalability of XenServer to many VMs and virtual devices.
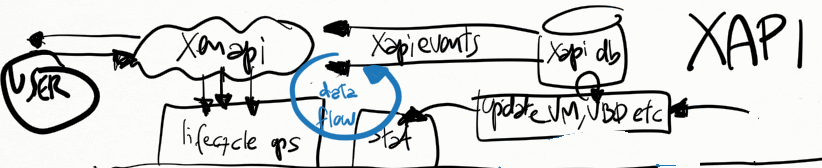
Xapi
Sending events from the xenapi
A xenapi user client, such as XenCenter, the xe-cli or a python script, can register to receive events from XAPI for specific objects in the XAPI DB. XAPI will generate events for those registered clients whenever the corresponding XAPI DB object changes.
This small python scripts shows how to register a simple event watch loop for XAPI:
import XenAPI
session = XenAPI.Session("http://xshost")
session.login_with_password("username","password")
session.xenapi.event.register(["VM","pool"]) # register for events in the pool and VM objects
while True:
try:
events = session.xenapi.event.next() # block until a xapi event on a xapi DB object is available
for event in events:
print "received event op=%s class=%s ref=%s" % (event['operation'], event['class'], event['ref'])
if event['class'] == 'vm' and event['operation'] == 'mod':
vm = event['snapshot']
print "xapi-event on vm: vm_uuid=%s, vm_name_label=%s, power_state=%s, current_operation=%s" % (vm['uuid'],vm['name_label'],vm['power_state'],vm['current_operations'].values())
except XenAPI.Failure, e:
if len(e.details) > 0 and e.details[0] == 'EVENTS_LOST':
session.xenapi.event.unregister(["VM","pool"])
session.xenapi.event.register(["VM","pool"])
Receiving events from xenopsd
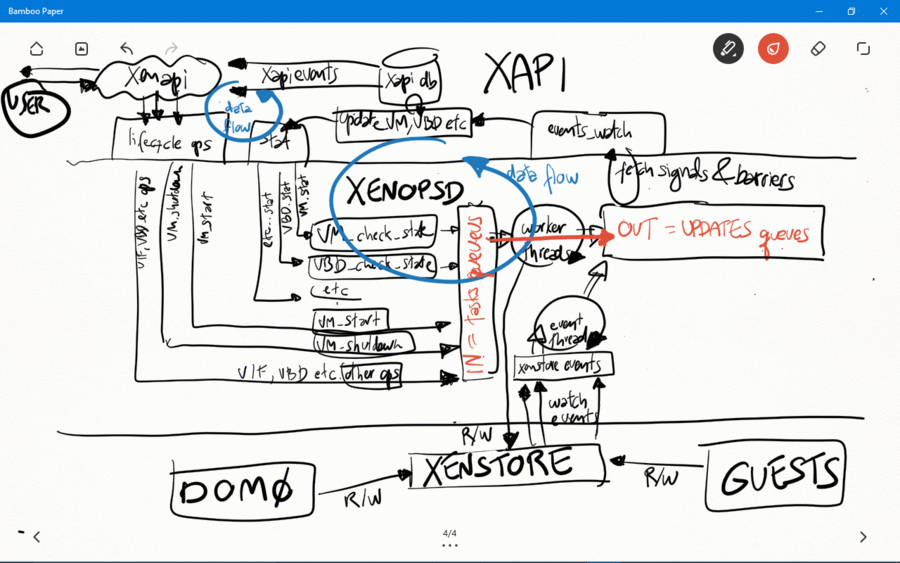
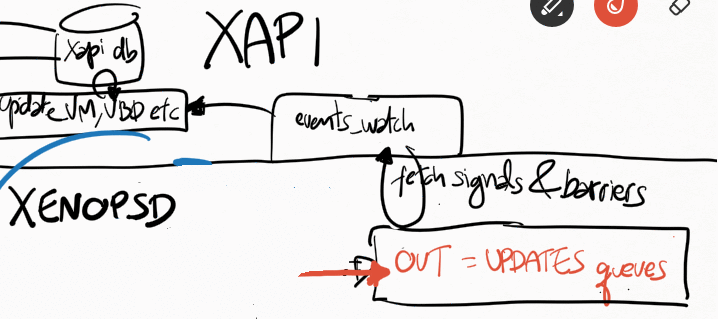
Xapi receives all events from xenopsd via the function xapi_xenops.events_watch() in its own independent thread. This is a single-threaded function that is responsible for handling all of the signals sent by xenopsd. In some situations with lots of VMs and virtual devices such as VBDs, this loop may saturate a single dom0 vcpu, which will slow down handling all of the xenopsd events and may cause the xenopsd signals to accumulate unboundedly in the worst case in the updates queue in xenopsd (see Figure 1).
The function xapi_xenops.events_watch() calls xenops_client.UPDATES.get() to obtain a list of (barrier, barrier_events), and then it process each one of the barrier_event, which can be one of the following events:
- Vm id: something changed in this VM, run xapi_xenops.update_vm() to query xenopsd about its state. The function update_vm() will update power_state, allowed_operations, console and guest_agent state in the xapi DB.
- Vbd id: something changed in this VM, run xapi_xenops.update_vbd() to query xenopsd about its state. The function update_vbd() will update currently_attached and connected in the xapi DB.
- Vif id: something changed in this VM, run xapi_xenops.update_vif() to query xenopsd about its state. The function update_vif() will update activate and plugged state of in the xapi DB.
- Pci id: something changed in this VM, run xapi_xenops.update_pci() to query xenopsd about its state.
- Vgpu id: something changed in this VM, run xapi_xenops.update_vgpu() to query xenopsd about its state.
- Task id: something changed in this VM, run xapi_xenops.update_task() to query xenopsd about its state. The function update_task() will update the progress of the task in the xapi DB using the information of the task in xenopsd.
All the xapi_xenops.update_X() functions above will call Xenopsd_client.X.stat() functions to obtain the current state of X from xenopsd:
There are a couple of optimisations while processing the events in xapi_xenops.events_watch():
- if an event X=(vm_id,dev_id) (eg. Vbd dev_id) has already been processed in a barrier_events, it’s not processed again. A typical value for X is eg. “<vm_uuid>.xvda” for a VBD.
- if Events_from_xenopsd.are_supressed X, then this event is ignored. Events are supressed if VM X.vm_id is migrating away from the host
Barriers
When xapi needs to execute (and to wait for events indicating completion of) a xapi operation (such as VM.start and VM.shutdown) containing many xenopsd sub-operations (such as VM.start – to force xenopsd to change the VM power_state, and VM.stat, VBD.stat, VIF.stat etc – to force the xapi DB to catch up with the xenopsd new state for these objects), xapi sends to the xenopsd input queue a barrier, indicating that xapi will then block and only continue execution of the barred operation when xenopsd returns the barrier. The barrier should only be returned when xenopsd has finished the execution of all the operations requested by xapi (such as VBD.stat and VM.stat in order to update the state of the VM in the xapi database after a VM.start has been issued to xenopsd).
A recent problem has been detected in the xapi_xenops.events_watch() function: when it needs to process many VM_check_state events, this may push for later the processing of barriers associated with a VM.start, delaying xapi in reporting (via a xapi event) that the VM state in the xapi DB has reached the running power_state. This needs further debugging, and is probably one of the reasons in CA-87377 why in some conditions a xapi event reporting that the VM power_state is running (causing it to go from yellow to green state in XenCenter) is taking so long to be returned, way after the VM is already running.
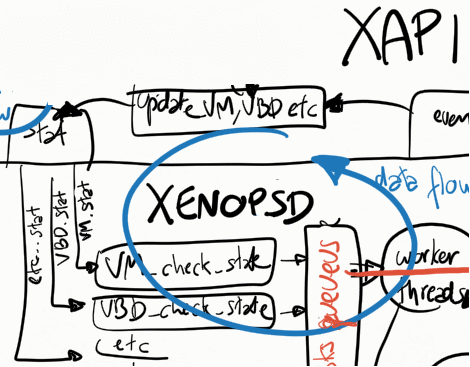
Xenopsd
Xenopsd has a few queues that are used by xapi to store commands to be executed (eg. VBD.stat) and update events to be picked up by xapi. The main ones, easily seen at runtime by running the following command in dom0, are:
# xenops-cli diagnostics --queue=org.xen.xapi.xenops.classic
{
queues: [ # XENOPSD INPUT QUEUE
... stuff that still needs to be processed by xenopsd
VM.stat
VBD.stat
VM.start
VM.shutdown
VIF.plug
etc
]
workers: [ # XENOPSD WORKER THREADS
... which stuff each worker thread is processing
]
updates: {
updates: [ # XENOPSD OUTPUT QUEUE
... signals from xenopsd that need to be picked up by xapi
VM_check_state
VBD_check_state
etc
]
} tasks: [ # XENOPSD TASKS
... state of each known task, before they are manually deleted after completion of the task
]
}Sending events to xapi
Whenever xenopsd changes the state of a XenServer object such as a VBD or VM, or when it receives an event from xenstore indicating that the states of these objects have changed (perhaps because either a guest or the dom0 backend changed the state of a virtual device), it creates a signal for the corresponding object (VM_check_state, VBD_check_state etc) and send it up to xapi. Xapi will then process this event in its xapi_xenops.events_watch() function.
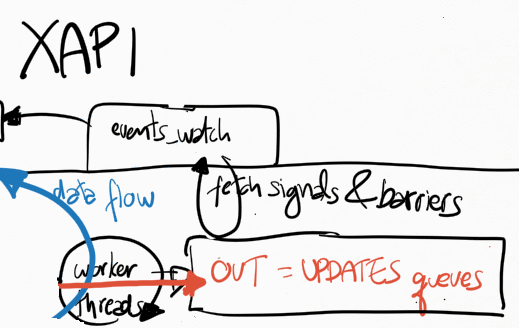
These signals may need to wait a long time to be processed if the single-threaded xapi_xenops.events_watch() function is having difficulties (ie taking a long time) to process previous signals in the UPDATES queue from xenopsd.
Receiving events from xenstore
Xenopsd watches a number of keys in xenstore, both in dom0 and in each guest. Xenstore is responsible to send watch events to xenopsd whenever the watched keys change state. Xenopsd uses a xenstore client library to make it easier to create a callback function that is called whenever xenstore sends these events.
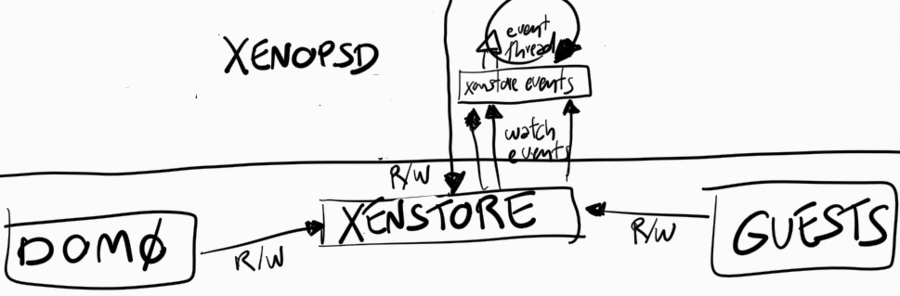
Xenopsd also needs to complement sometimes these watch events with polling of some values. An example is the @introduceDomain event in xenstore (handled in xenopsd/xc/xenstore_watch.ml), which indicates that a new VM has been created. This event unfortunately does not indicate the domid of the VM, and xenopsd needs to query Xen (via libxc) which domains are now available in the host and compare with the previous list of known domains, in order to figure out the domid of the newly introduced domain.
It is not good practice to poll xenstore for changes of values. This will add a large overhead to both xenstore and xenopsd, and decrease the scalability of XenServer in terms of number of VMs/host and virtual devices per VM. A much better approach is to rely on the watch events of xenstore to indicate when a specific value has changed in xenstore.
Xenstore
Sending events to xenstore clients
If a xenstore client has created watch events for a key, then xenstore will send events to this client whenever this key changes state.
Receiving events from xenstore clients
Xenstore clients indicate to xenstore that something state changed by writing to some xenstore key. This may or may not cause xenstore to create watch events for the corresponding key, depending on if other xenstore clients have watches on this key.
High-Availability
High-Availability (HA) tries to keep VMs running, even when there are hardware failures in the resource pool, when the admin is not present. Without HA the following may happen:
- during the night someone spills a cup of coffee over an FC switch; then
- VMs running on the affected hosts will lose access to their storage; then
- business-critical services will go down; then
- monitoring software will send a text message to an off-duty admin; then
- the admin will travel to the office and fix the problem by restarting the VMs elsewhere.
With HA the following will happen:
- during the night someone spills a cup of coffee over an FC switch; then
- VMs running on the affected hosts will lose access to their storage; then
- business-critical services will go down; then
- the HA software will determine which hosts are affected and shut them down; then
- the HA software will restart the VMs on unaffected hosts; then
- services are restored; then on the next working day
- the admin can arrange for the faulty switch to be replaced.
HA is designed to handle an emergency and allow the admin time to fix failures properly.
Example
The following diagram shows an HA-enabled pool, before and after a network link between two hosts fails.
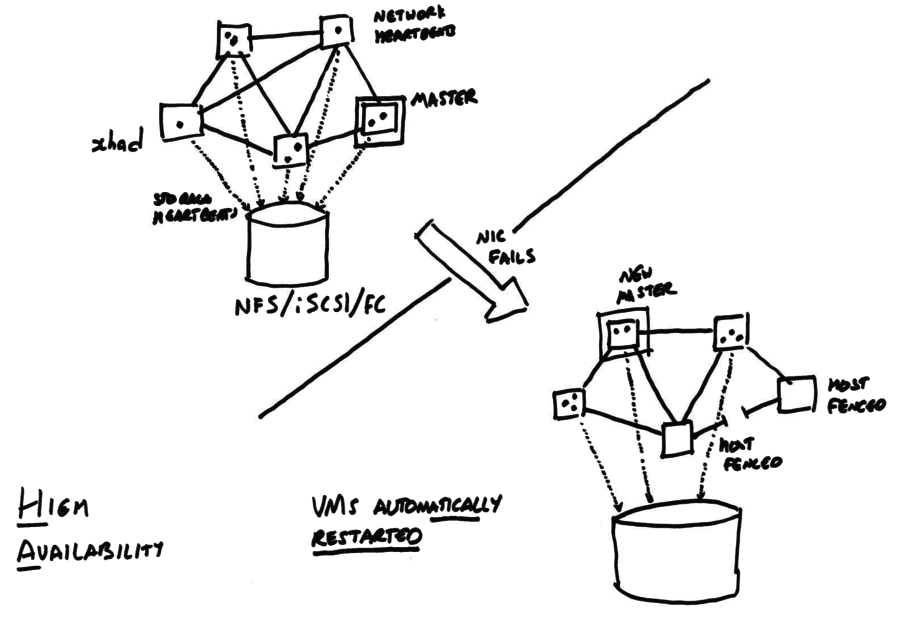
When HA is enabled, all hosts in the pool
- exchange periodic heartbeat messages over the network
- send heartbeats to a shared storage device.
- attempt to acquire a “master lock” on the shared storage.
HA is designed to recover as much as possible of the pool after a single failure i.e. it removes single points of failure. When some subset of the pool suffers a failure then the remaining pool members
- figure out whether they are in the largest fully-connected set (the
“liveset”);
- if they are not in the largest set then they “fence” themselves (i.e. force reboot via the hypervisor watchdog)
- elect a master using the “master lock”
- restart all lost VMs.
After HA has recovered a pool, it is important that the original failure is addressed because the remaining pool members may not be able to cope with any more failures.
Design
HA must never violate the following safety rules:
- there must be at most one master at all times. This is because the master holds the VM and disk locks.
- there must be at most one instance of a particular VM at all times. This is because starting the same VM twice will result in severe filesystem corruption.
However to be useful HA must:
- detect failures quickly;
- minimise the number of false-positives in the failure detector; and
- make the failure handling logic as robust as possible.
The implementation difficulty arises when trying to be both useful and safe at the same time.
Terminology
We use the following terminology:
- fencing: also known as I/O fencing, refers to the act of isolating a host from network and storage. Once a host has been fenced, any VMs running there cannot generate side-effects observable to a third party. This means it is safe to restart the running VMs on another node without violating the safety-rule and running the same VM simultaneously in two locations.
- heartbeating: exchanging status updates with other hosts at regular pre-arranged intervals. Heartbeat messages reveal that hosts are alive and that I/O paths are working.
- statefile: a shared disk (also known as a “quorum disk”) on the “Heartbeat” SR which is mapped as a block device into every host’s domain 0. The shared disk acts both as a channel for heartbeat messages and also as a building block of a Pool master lock, to prevent multiple hosts becoming masters in violation of the safety-rule (a dangerous situation also known as “split-brain”).
- management network: the network over which the XenAPI XML/RPC requests flow and also used to send heartbeat messages.
- liveset: a per-Host view containing a subset of the Hosts in the Pool
which are considered by that Host to be alive i.e. responding to XenAPI
commands and running the VMs marked as
resident_onthere. When a Hostbleaves the liveset as seen by Hostait is safe for Hostato assume that Hostbhas been fenced and to take recovery actions (e.g. restarting VMs), without violating either of the safety-rules. - properly shared SR: an SR which has field
shared=true; and which has aPBDconnecting it to everyenabledHost in the Pool; and where each of thesePBDs has fieldcurrently_attachedset to true. A VM whose disks are in a properly shared SR could be restarted on anyenabledHost, memory and network permitting. - properly shared Network: a Network which has a
PIFconnecting it to everyenabledHost in the Pool; and where each of thesePIFs has fieldcurrently_attachedset to true. A VM whose VIFs connect to properly shared Networks could be restarted on anyenabledHost, memory and storage permitting. - agile: a VM is said to be agile if all disks are in properly shared SRs and all network interfaces connect to properly shared Networks.
- unprotected: an unprotected VM has field
ha_always_runset to false and will never be restarted automatically on failure or have reconfiguration actions blocked by the HA overcommit protection. - best-effort: a best-effort VM has fields
ha_always_runset to true andha_restart_priorityset to best-effort. A best-effort VM will only be restarted if (i) the failure is directly observed; and (ii) capacity exists for an immediate restart. No more than one restart attempt will ever be made. - protected: a VM is said to be protected if it will be restarted by HA
i.e. has field
ha_always_runset to true and fieldha_restart_prioritynot set to `best-effort. - survival rule 1: describes the situation where hosts survive
because they are in the largest network partition with statefile access.
This is the normal state of the
xhaddaemon. - survival rule 2: describes the situation where all hosts have lost access to the statefile but remain alive while they can all see each-other on the network. In this state any further failure will cause all nodes to self-fence. This state is intended to cope with the system-wide temporary loss of the storage service underlying the statefile.
Assumptions
We assume:
- All I/O used for monitoring the health of hosts (i.e. both storage and network-based heartbeating) is along redundant paths, so that it survives a single hardware failure (e.g. a broken switch or an accidentally-unplugged cable). It is up to the admin to ensure their environment is setup correctly.
- The hypervisor watchdog mechanism will be able to guarantee the isolation of nodes, once communication has been lost, within a pre-arranged time period. Therefore no active power fencing equipment is required.
- VMs may only be marked as protected if they are fully agile i.e. able to run on any host, memory permitting. No additional constraints of any kind may be specified e.g. it is not possible to make “CPU reservations”.
- Pools are assumed to be homogenous with respect to CPU type and presence of
VT/SVM support (also known as “HVM”). If a Pool is created with
non-homogenous hosts using the
--forceflag then the additional constraints will not be noticed by the VM failover planner resulting in runtime failures while trying to execute the failover plans. - No attempt will ever be made to shutdown or suspend “lower” priority VMs to guarantee the survival of “higher” priority VMs.
- Once HA is enabled it is not possible to reconfigure the management network or the SR used for storage heartbeating.
- VMs marked as protected are considered to have failed if they are offline i.e. the VM failure handling code is level-sensitive rather than edge-sensitive.
- VMs marked as best-effort are considered to have failed only when the host where they are resident is declared offline i.e. the best-effort VM failure handling code is edge-sensitive rather than level-sensitive. A single restart attempt is attempted and if this fails no further start is attempted.
- HA can only be enabled if all Pool hosts are online and actively responding to requests.
- when HA is enabled the database is configured to write all updates to the “Heartbeat” SR, guaranteeing that VM configuration changes are not lost when a host fails.
Components
The implementation is split across the following components:
- xhad: the cluster membership daemon maintains a quorum of hosts through network and storage heartbeats
- xapi: used to configure the HA policy i.e. which network and storage to use for heartbeating and which VMs to restart after a failure.
- xen: the Xen watchdog is used to reliably fence the host when the host has been (partially or totally) isolated from the cluster
To avoid a “split-brain”, the cluster membership daemon must “fence” (i.e. isolate) nodes when they are not part of the cluster. In general there are 2 approaches:
- cut the power of remote hosts which you can’t talk to on the network any more. This is the approach taken by most open-source clustering software since it is simpler. However it has the downside of requiring the customer buy more hardware and set it up correctly.
- rely on the remote hosts using a watchdog to cut their own power (i.e. halt or reboot) after a timeout. This relies on the watchdog being reliable. Most other people don’t trust the Linux watchdog; after all the Linux kernel is highly threaded, performs a lot of (useful) functions and kernel bugs which result in deadlocks do happen. We use the Xen watchdog because we believe that the Xen hypervisor is simple enough to reliably fence the host (via triggering a reboot of domain 0 which then triggers a host reboot).
xhad
xhad is the cluster membership daemon: it exchanges heartbeats with the other nodes to determine which nodes are still in the cluster (the “live set”) and which nodes have definitely failed (through watchdog fencing). When a host has definitely failed, xapi will unlock all the disks and restart the VMs according to the HA policy.
Since Xapi is a critical part of the system, the xhad also acts as a Xapi watchdog. It polls Xapi every few seconds and checks if Xapi can respond. If Xapi seems to have failed then xhad will restart it. If restarts continue to fail then xhad will consider the host to have failed and self-fence.
xhad is configured via a simple config file written on each host in
/etc/xensource/xhad.conf. The file must be identical on each host
in the cluster. To make changes to the file, HA must be disabled and then
re-enabled afterwards. Note it may not be possible to re-enable HA depending
on the configuration change (e.g. if a host has been added but that host has
a broken network configuration then this will block HA enable).
The xhad.conf file is written in XML and contains
- pool-wide configuration: this includes a list of all hosts which should be in the liveset and global timeout information
- local host configuration: this identifies the local host and described which local network interface and block device to use for heartbeating.
The following is an example xhad.conf file:
<?xml version="1.0" encoding="utf-8"?>
<xhad-config version="1.0">
<!--pool-wide configuration-->
<common-config>
<GenerationUUID>xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx</GenerationUUID>
<UDPport>694</UDPport>
<!--for each host, specify host UUID, and IP address-->
<host>
<HostID>xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx</HostID>
<IPaddress>xxx.xxx.xxx.xx1</IPaddress>
</host>
<host>
<HostID>xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx</HostID>
<IPaddress>xxx.xxx.xxx.xx2</IPaddress>
</host>
<host>
<HostID>xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx</HostID>
<IPaddress>xxx.xxx.xxx.xx3</IPaddress>
</host>
<!--optional parameters [sec] -->
<parameters>
<HeartbeatInterval>4</HeartbeatInterval>
<HeartbeatTimeout>30</HeartbeatTimeout>
<StateFileInterval>4</StateFileInterval>
<StateFileTimeout>30</StateFileTimeout>
<HeartbeatWatchdogTimeout>30</HeartbeatWatchdogTimeout>
<StateFileWatchdogTimeout>45</StateFileWatchdogTimeout>
<BootJoinTimeout>90</BootJoinTimeout>
<EnableJoinTimeout>90</EnableJoinTimeout>
<XapiHealthCheckInterval>60</XapiHealthCheckInterval>
<XapiHealthCheckTimeout>10</XapiHealthCheckTimeout>
<XapiRestartAttempts>1</XapiRestartAttempts>
<XapiRestartTimeout>30</XapiRestartTimeout>
<XapiLicenseCheckTimeout>30</XapiLicenseCheckTimeout>
</parameters>
</common-config>
<!--local host configuration-->
<local-config>
<localhost>
<HostID>xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx2</HostID>
<HeartbeatInterface> xapi1</HeartbeatInterface>
<HeartbeatPhysicalInterface>bond0</HeartbeatPhysicalInterface>
<StateFile>/dev/statefiledevicename</StateFile>
</localhost>
</local-config>
</xhad-config>The fields have the following meaning:
- GenerationUUID: a UUID generated each time HA is reconfigured. This allows xhad to tell an old host which failed; had been removed from the configuration; repaired and then restarted that the world has changed while it was away.
- UDPport: the port number to use for network heartbeats. It’s important to allow this traffic through the firewall and to make sure the same port number is free on all hosts (beware of portmap services occasionally binding to it).
- HostID: a UUID identifying a host in the pool. We would normally use xapi’s notion of a host uuid.
- IPaddress: any IP address on the remote host. We would normally use xapi’s notion of a management network.
- HeartbeatTimeout: if a heartbeat packet is not received for this many
seconds, then xhad considers the heartbeat to have failed. This is
the user-supplied “HA timeout” value, represented below as
T.Tmust be bigger than 10; we would normally use 60s. - StateFileTimeout: if a storage update is not seen for a host for this
many seconds, then xhad considers the storage heartbeat to have failed.
We would normally use the same value as the HeartbeatTimeout
T. - HeartbeatInterval: interval between heartbeat packets sent. We would
normally use a value
2 <= t <= 6, derived from the user-supplied HA timeout viat = (T + 10) / 10 - StateFileInterval: interval betwen storage updates (also known as “statefile updates”). This would normally be set to the same value as HeartbeatInterval.
- HeartbeatWatchdogTimeout: If the host does not send a heartbeat for this
amount of time then the host self-fences via the Xen watchdog. We normally
set this to
T. - StateFileWatchdogTimeout: If the host does not update the statefile for
this amount of time then the host self-fences via the Xen watchdog. We
normally set this to
T+15. - BootJoinTimeout: When the host is booting and joining the liveset (i.e.
the cluster), consider the join a failure if it takes longer than this
amount of time. We would normally set this to
T+60. - EnableJoinTimeout: When the host is enabling HA for the first time,
consider the enable a failure if it takes longer than this amount of time.
We would normally set this to
T+60. - XapiHealthCheckInterval: Interval between “health checks” where we run a script to check whether Xapi is responding or not.
- XapiHealthCheckTimeout: Number of seconds to wait before assuming that Xapi has deadlocked during a “health check”.
- XapiRestartAttempts: Number of Xapi restarts to attempt before concluding Xapi has permanently failed.
- XapiRestartTimeout: Number of seconds to wait for a Xapi restart to complete before concluding it has failed.
- XapiLicenseCheckTimeout: Number of seconds to wait for a Xapi license check to complete before concluding that xhad should terminate.
In addition to the config file, Xhad exposes a simple control API which is exposed as scripts:
ha_set_pool_state (Init | Invalid): sets the global pool state to “Init” (before starting HA) or “Invalid” (causing all other daemons who can see the statefile to shutdown)ha_start_daemon: if the pool state is “Init” then the daemon will attempt to contact other daemons and enable HA. If the pool state is “Active” then the host will attempt to join the existing liveset.ha_query_liveset: returns the current state of the cluster.ha_propose_master: returns whether the current node has been elected pool master.ha_stop_daemon: shuts down the xhad on the local host. Note this will not disarm the Xen watchdog by itself.ha_disarm_fencing: disables fencing on the local host.ha_set_excluded: when a host is being shutdown cleanly, record the fact that the VMs have all been shutdown so that this host can be ignored in future cluster membership calculations.
Fencing
Xhad continuously monitors whether the host should remain alive, or if it should self-fence. There are two “survival rules” which will keep a host alive; if neither rule applies (or if xhad crashes or deadlocks) then the host will fence. The rules are:
- Xapi is running; the storage heartbeats are visible; this host is a member of the “best” partition (as seen through the storage heartbeats)
- Xapi is running; the storage is inaccessible; all hosts which should be running (i.e. not those “excluded” by being cleanly shutdown) are online and have also lost storage access (as seen through the network heartbeats).
where the “best” partition is the largest one if that is unique, or if there are multiple partitions of the same size then the one containing the lowest host uuid is considered best.
The first survival rule is the “normal” case. The second rule exists only to prevent the storage from becoming a single point of failure: all hosts can remain alive until the storage is repaired. Note that if a host has failed and has not yet been repaired, then the storage becomes a single point of failure for the degraded pool. HA removes single point of failures, but multiple failures can still cause problems. It is important to fix failures properly after HA has worked around them.
xapi
Xapi is responsible for
- exposing an interface for setting HA policy
- creating VDIs (disks) on shared storage for heartbeating and storing the pool database
- arranging for these disks to be attached on host boot, before the “SRmaster” is online
- configuring and managing the
xhadheartbeating daemon
The HA policy APIs include
- methods to determine whether a VM is agile i.e. can be restarted in principle on any host after a failure
- planning for a user-specified number of host failures and enforcing access control
- restarting failed protected VMs in policy order
The HA policy settings are stored in the Pool database which is written (synchronously) to a VDI in the same SR that’s being used for heartbeating. This ensures that the database can be recovered after a host fails and the VMs are recovered.
Xapi stores 2 settings in its local database:
- ha_disable_failover_actions: this is set to false when we want nodes to be able to recover VMs – this is the normal case. It is set to true during the HA disable process to prevent a split-brain forming while HA is only partially enabled.
- ha_armed: this is set to true to tell Xapi to start
Xhadduring host startup and wait to join the liveset.
Disks on shared storage
The regular disk APIs for creating, destroying, attaching, detaching (etc)
disks need the SRmaster (usually but not always the Pool master) to be
online to allow the disks to be locked. The SRmaster cannot be brought
online until the host has joined the liveset. Therefore we have a
cyclic dependency: joining the liveset needs the statefile disk to be attached
but attaching a disk requires being a member of the liveset already.
The dependency is broken by adding an explicit “unlocked” attach storage
API called VDI_ATTACH_FROM_CONFIG. Xapi uses the VDI_GENERATE_CONFIG API
during the HA enable operation and stores away the result. When the system
boots the VDI_ATTACH_FROM_CONFIG is able to attach the disk without the
SRmaster.
The role of Host.enabled
The Host.enabled flag is used to mean, “this host is ready to start VMs and
should be included in failure planning”.
The VM restart planner assumes for simplicity that all protected VMs can
be started anywhere; therefore all involved networks and storage must be
properly shared.
If a host with an unplugged PBD were to become enabled then the corresponding
SR would cease to be properly shared, all the VMs would cease to be
agile and the VM restart logic would fail.
To ensure the VM restart logic always works, great care is taken to make sure that Hosts may only become enabled when their networks and storage are properly configured. This is achieved by:
- when the master boots and initialises its database it sets all Hosts to dead and disabled and then signals the HA background thread (signal_database_state_valid) to wake up from sleep and start processing liveset information (and potentially setting hosts to live)
- when a slave calls Pool.hello (i.e. after the slave has rebooted), the master sets it to disabled, allowing it a grace period to plug in its storage;
- when a host (master or slave) successfully plugs in its networking and storage it calls consider_enabling_host which checks that the preconditions are met and then sets the host to enabled; and
- when a slave notices its database connection to the master restart
(i.e. after the master
xapihas just restarted) it callsconsider_enabling_host}
The steady-state
When HA is enabled and all hosts are running normally then each calls
ha_query_liveset every 10s.
Slaves check to see if the host they believe is the master is alive and has
the master lock. If another node has become master then the slave will
rewrite its pool.conf and restart. If no node is the master then the
slave will call
on_master_failure,
proposing itself and, if it is rejected,
checking the liveset to see which node acquired the lock.
The master monitors the liveset and updates the Host_metrics.live flag
of every host to reflect the liveset value. For every host which is not in
the liveset (i.e. has fenced) it enumerates all resident VMs and marks them
as Halted. For each protected VM which is not running, the master computes
a VM restart plan and attempts to execute it. If the plan fails then a
best-effort VM.start call is attempted. Finally an alert is generated if
the VM could not be restarted.
Note that XenAPI heartbeats are still sent when HA is enabled, even though
they are not used to drive the values of the Host_metrics.live field.
Note further that, when a host is being shutdown, the host is immediately
marked as dead and its host reference is added to a list used to prevent the
Host_metrics.live being accidentally reset back to live again by the
asynchronous liveset query. The Host reference is removed from the list when
the host restarts and calls Pool.hello.
Planning and overcommit
The VM failover planning code is sub-divided into two pieces, stored in separate files:
- binpack.ml: contains two algorithms for packing items of different sizes (i.e. VMs) into bins of different sizes (i.e. Hosts); and
- xapi_ha_vm_failover.ml: interfaces between the Pool database and the binpacker; also performs counterfactual reasoning for overcommit protection.
The input to the binpacking algorithms are configuration values which represent an abstract view of the Pool:
type ('a, 'b) configuration = {
hosts: ('a * int64) list; (** a list of live hosts and free memory *)
vms: ('b * int64) list; (** a list of VMs and their memory requirements *)
placement: ('b * 'a) list; (** current VM locations *)
total_hosts: int; (** total number of hosts in the pool 'n' *)
num_failures: int; (** number of failures to tolerate 'r' *)
}Note that:
- the memory required by the VMs listed in
placementhas already been substracted from the free memory of the hosts; it doesn’t need to be subtracted again. - the free memory of each host has already had per-host miscellaneous overheads subtracted from it, including that used by unprotected VMs, which do not appear in the VM list.
- the total number of hosts in the pool (
total_hosts) is a constant for any particular invocation of HA. - the number of failures to tolerate (
num_failures) is the user-settable value from the XenAPIPool.ha_host_failures_to_tolerate.
There are two algorithms which satisfy the interface:
sig
plan_always_possible: ('a, 'b) configuration -> bool;
get_specific_plan: ('a, 'b) configuration -> 'b list -> ('b * 'a) list
endThe function get_specific_plan takes a configuration and a list of VMs(
the host where they are resident on have failed). It returns a VM restart
plan represented as a VM to Host association list. This is the function
called by the background HA VM restart thread on the master.
The function plan_always_possible returns true if every sequence of Host
failures of length
num_failures (irrespective of whether all hosts failed at once, or in
multiple separate episodes)
would result in calls to get_specific_plan which would allow all protected
VMs to be restarted.
This function is heavily used by the overcommit protection logic as well as code in XenCenter which aims to
maximise failover capacity using the counterfactual reasoning APIs:
Pool.ha_compute_max_host_failures_to_tolerate
Pool.ha_compute_hypothetical_max_host_failures_to_tolerateThere are two binpacking algorithms: the more detailed but expensive
algorithmm is used for smaller/less
complicated pool configurations while the less detailed, cheaper algorithm
is used for the rest. The
choice between algorithms is based only on total_hosts (n) and
num_failures (r).
Note that the choice of algorithm will only change if the number of Pool
hosts is varied (requiring HA to be disabled and then enabled) or if the
user requests a new num_failures target to plan for.
The expensive algorithm uses an exchaustive search with a “biggest-fit-decreasing” strategy that takes the biggest VMs first and allocates them to the biggest remaining Host. The implementation keeps the VMs and Hosts as sorted lists throughout. There are a number of transformations to the input configuration which are guaranteed to preserve the existence of a VM to host allocation (even if the actual allocation is different). These transformations which are safe are:
- VMs may be removed from the list
- VMs may have their memory requirements reduced
- Hosts may be added
- Hosts may have additional memory added.
The cheaper algorithm is used for larger Pools where the state space to search is too large. It uses the same “biggest-fit-decreasing” strategy with the following simplifying approximations:
- every VM that fails is as big as the biggest
- the number of VMs which fail due to a single Host failure is always the maximum possible (even if these are all very small VMs)
- the largest and most capable Hosts fail
An informal argument that these approximations are safe is as follows: if the maximum number of VMs fail, each of which is size of the largest and we can find a restart plan using only the smaller hosts then any real failure:
- can never result in the failure of more VMs;
- can never result in the failure of bigger VMs; and
- can never result in less host capacity remaining.
Therefore we can take this almost-certainly-worse-than-worst-case failure plan and:
- replace the remaining hosts in the worst case plan with the real remaining hosts, which will be the same size or larger; and
- replace the failed VMs in the worst case plan with the real failed VMs, which will be fewer or the same in number and smaller or the same in size.
Note that this strategy will perform best when each host has the same number of VMs on it and when all VMs are approximately the same size. If one very big VM exists and a lot of smaller VMs then it will probably fail to find a plan. It is more tolerant of differing amounts of free host memory.
Overcommit protection
Overcommit protection blocks operations which would prevent the Pool being able to restart protected VMs after host failure. The Pool may become unable to restart protected VMs in two general ways: (i) by running out of resource i.e. host memory; and (ii) by altering host configuration in such a way that VMs cannot be started (or the planner thinks that VMs cannot be started).
API calls which would change the amount of host memory currently in use
(VM.start, VM.resume, VM.migrate etc)
have been modified to call the planning functions supplying special
“configuration change” parameters.
Configuration change values represent the proposed operation and have type
type configuration_change = {
(** existing VMs which are leaving *)
old_vms_leaving: (API.ref_host * (API.ref_VM * API.vM_t)) list;
(** existing VMs which are arriving *)
old_vms_arriving: (API.ref_host * (API.ref_VM * API.vM_t)) list;
(** hosts to pretend to disable *)
hosts_to_disable: API.ref_host list;
(** new number of failures to consider *)
num_failures: int option;
(** new VMs to restart *)
new_vms_to_protect: API.ref_VM list;
}A VM migration will be represented by saying the VM is “leaving” one host and “arriving” at another. A VM start or resume will be represented by saying the VM is “arriving” on a host.
Note that no attempt is made to integrate the overcommit protection with the
general VM.start host chooser as this would be quite expensive.
Note that the overcommit protection calls are written as asserts called
within the message forwarder in the master, holding the main forwarding lock.
API calls which would change the system configuration in such a way as to prevent the HA restart planner being able to guarantee to restart protected VMs are also blocked. These calls include:
VBD.create: where the disk is not in a properly shared SRVBD.insert: where the CDROM is local to a hostVIF.create: where the network is not properly sharedPIF.unplug: when the network would cease to be properly sharedPBD.unplug: when the storage would cease to be properly sharedHost.enable: when some network or storage would cease to be properly shared (e.g. if this host had a broken storage configuration)
xen
The Xen hypervisor has per-domain watchdog counters which, when enabled, decrement as time passes and can be reset from a hypercall from the domain. If the domain fails to make the hypercall and the timer reaches zero then the domain is immediately shutdown with reason reboot. We configure Xen to reboot the host when domain 0 enters this state.
High-level operations
Enabling HA
Before HA can be enabled the admin must take care to configure the environment properly. In particular:
- NIC bonds should be available for network heartbeats;
- multipath should be configured for the storage heartbeats;
- all hosts should be online and fully-booted.
The XenAPI client can request a specific shared SR to be used for
storage heartbeats, otherwise Xapi will use the Pool’s default SR.
Xapi will use VDI_GENERATE_CONFIG to ensure the disk will be attached
automatically on system boot before the liveset has been joined.
Note that extra effort is made to re-use any existing heartbeat VDIS so that
- if HA is disabled with some hosts offline, when they are rebooted they stand a higher chance of seeing a well-formed statefile with an explicit invalid state. If the VDIs were destroyed on HA disable then hosts which boot up later would fail to attach the disk and it would be harder to distinguish between a temporary storage failure and a permanent HA disable.
- the heartbeat SR can be created on expensive low-latency high-reliability storage and made as small as possible (to minimise infrastructure cost), safe in the knowledge that if HA enables successfully once, it won’t run out of space and fail to enable in the future.
The Xapi-to-Xapi communication looks as follows:

The Xapi Pool master calls Host.ha_join_liveset on all hosts in the
pool simultaneously. Each host
runs the ha_start_daemon script
which starts Xhad. Each Xhad starts exchanging heartbeats over the network
and storage defined in the xhad.conf.
Joining a liveset

The Xhad instances exchange heartbeats and decide which hosts are in the “liveset” and which have been fenced.
After joining the liveset, each host clears the “excluded” flag which would have been set if the host had been shutdown cleanly before – this is only needed when a host is shutdown cleanly and then restarted.
Xapi periodically queries the state of xhad via the ha_query_liveset
command. The state will be Starting until the liveset is fully
formed at which point the state will be Online.
When the ha_start_daemon script returns then Xapi will decide
whether to stand for master election or not. Initially when HA is being
enabled and there is a master already, this node will be expected to
stand unopposed. Later when HA notices that the master host has been
fenced, all remaining hosts will stand for election and one of them will
be chosen.
Shutting down a host

When a host is to be shutdown cleanly, it can be safely “excluded” from the pool such that a future failure of the storage heartbeat will not cause all pool hosts to self-fence (see survival rule 2 above). When a host is “excluded” all other hosts know that the host does not consider itself a master and has no resources locked i.e. no VMs are running on it. An excluded host will never allow itself to form part of a “split brain”.
Once a host has given up its master role and shutdown any VMs, it is safe
to disable fencing with ha_disarm_fencing and stop xhad with
ha_stop_daemon. Once the daemon has been stopped the “excluded”
bit can be set in the statefile via ha_set_excluded and the
host safely rebooted.
Restarting a host
When a host restarts after a failure Xapi notices that ha_armed is set in the local database. Xapi
- runs the
attach-static-vdisscript to attach the statefile and database VDIs. This can fail if the storage is inaccessible; Xapi will retry until it succeeds. - runs the ha_start_daemon to join the liveset, or determine that HA has been cleanly disabled (via setting the state to Invalid).
In the special case where Xhad fails to access the statefile and the host used to be a slave then Xapi will try to contact the previous master and find out
- who the new master is;
- whether HA is enabled on the Pool or not.
If Xapi can confirm that HA was disabled then it will disarm itself and join the new master. Otherwise it will keep waiting for the statefile to recover.
In the special case where the statefile has been destroyed and cannot be recovered, there is an emergency HA disable API the admin can use to assert that HA really has been disabled, and it’s not simply a connectivity problem. Obviously this API should only be used if the admin is totally sure that HA has been disabled.
Disabling HA
There are 2 methods of disabling HA: one for the “normal” case when the statefile is available; and the other for the “emergency” case when the statefile has failed and can’t be recovered.
Disabling HA cleanly

HA can be shutdown cleanly when the statefile is working i.e. when hosts
are alive because of survival rule 1. First the master Xapi tells the local
Xhad to mark the pool state as “invalid” using ha_set_pool_state.
Every xhad instance will notice this state change the next time it performs
a storage heartbeat. The Xhad instances will shutdown and Xapi will notice
that HA has been disabled the next time it attempts to query the liveset.
If a host loses access to the statefile (or if none of the hosts have access to the statefile) then HA can be disabled uncleanly.
Disabling HA uncleanly
The Xapi master first calls Host.ha_disable_failover_actions on each host
which sets ha_disable_failover_decisions in the lcoal database. This
prevents the node rebooting, gaining statefile access, acquiring the
master lock and restarting VMs when other hosts have disabled their
fencing (i.e. a “split brain”).

Once the master is sure that no host will suddenly start recovering VMs
it is safe to call Host.ha_disarm_fencing which runs the script
ha_disarm_fencing and then shuts down the Xhad with ha_stop_daemon.
Add a host to the pool
We assume that adding a host to the pool is an operation the admin will perform manually, so it is acceptable to disable HA for the duration and to re-enable it afterwards. If a failure happens during this operation then the admin will take care of it by hand.
Multi-version drivers
Linux loads device drivers on boot and every device driver exists in one version. XAPI extends this scheme such that device drivers may exist in multiple variants plus a mechanism to select the variant being loaded on boot. Such a driver is called a multi-version driver and we expect only a small subset of drivers, built and distributed by XenServer, to have this property. The following covers the background, API, and CLI for multi-version drivers in XAPI.
Variant vs. Version
A driver comes in several variants, each of which has a version. A variant may be updated to a later version while retaining its identity. This makes variants and versions somewhat synonymous and is admittedly confusing.
Device Drivers in Linux and XAPI
Drivers that are not compiled into the kernel are loaded dynamically from the file system. They are loaded from the hierarchy
/lib/modules/<kernel-version>/
and we are particularly interested in the hierarchy
/lib/modules/<kernel-version>/updates/
where vendor-supplied (“driver disk”) drivers are located and where we
want to support multiple versions. A driver has typically file extension
.ko (kernel object).
A presence in the file system does not mean that a driver is loaded as this happens only on demand. The actually loaded drivers (or modules, in Linux parlance) can be observed from
/proc/modules
netlink_diag 16384 0 - Live 0x0000000000000000
udp_diag 16384 0 - Live 0x0000000000000000
tcp_diag 16384 0 - Live 0x0000000000000000which includes dependencies between modules (the - means no dependencies).
Driver Properties
A driver name is unique and a driver can be loaded only once. The fact that kernel object files are located in a file system hierarchy means that a driver may exist multiple times and in different version in the file system. From the kernel’s perspective a driver has a unique name and is loaded at most once. We thus can talk about a driver using its name and acknowledge it may exist in different versions in the file system.
A driver that is loaded by the kernel we call active.
A driver file (
name.ko) that is in a hierarchy searched by the kernel is called selected. If the kernel needs the driver of that name, it would load this object file.
For a driver (name.ko) selection and activation are independent
properties:
- inactive, deselected: not loaded now and won’t be loaded on next boot.
- active, deselected: currently loaded but won’t be loaded on next boot.
- inactive, selected: not loaded now but will be loaded on demand.
- active, selected: currently loaded and will be loaded on demand after a reboot.
For a driver to be selected it needs to be in the hierarchy searched by the kernel. By removing a driver from the hierarchy it can be de-selected. This is possible even for drivers that are already loaded. Hence, activation and selection are independent.
Multi-Version Drivers
To support multi-version drivers, XenServer introduces a new hierarchy in Dom0. This is mostly technical background because a lower-level tool deals with this and not XAPI directly.
/lib/modules/<kernel-version>/updates/is searched by the kernel for drivers.- The hierarchy is expected to contain symbolic links to the file
actually containing the driver:
/lib/modules/<kernel-version>/xenserver/<driver>/<version>/<name>.ko
The xenserver hierarchy provides drivers in several versions. To
select a particular version, we expect a symbolic link from
updates/<name>.ko to <driver>/<version>/<name>.ko. At the next boot,
the kernel will search the updates/ entries and load the linked
driver, which will become active.
Example filesystem hierarchy:
/lib/
└── modules
└── 4.19.0+1 ->
├── updates
│ ├── aacraid.ko
│ ├── bnx2fc.ko -> ../xenserver/bnx2fc/2.12.13/bnx2fc.ko
│ ├── bnx2i.ko
│ ├── cxgb4i.ko
│ ├── cxgb4.ko
│ ├── dell_laptop.ko -> ../xenserver/dell_laptop/1.2.3/dell_laptop.ko
│ ├── e1000e.ko
│ ├── i40e.ko
│ ├── ice.ko -> ../xenserver/intel-ice/1.11.17.1/ice.ko
│ ├── igb.ko
│ ├── smartpqi.ko
│ └── tcm_qla2xxx.ko
└── xenserver
├── bnx2fc
│ ├── 2.12.13
│ │ └── bnx2fc.ko
│ └── 2.12.20-dell
│ └── bnx2fc.ko
├── dell_laptop
│ └── 1.2.3
│ └── dell_laptop.ko
└── intel-ice
├── 1.11.17.1
│ └── ice.ko
└── 1.6.4
└── ice.koSelection of a driver is synonymous with creating a symbolic link to the desired version.
Versions
The version of a driver is encoded in the path to its object file but
not in the name itself: for xenserver/intel-ice/1.11.17.1/ice.ko the
driver name is ice and only its location hints at the version.
The kernel does not reveal the location from where it loaded an active driver. Hence the name is not sufficient to observe the currently active version. For this, we use ELF notes.
The driver file (name.ko) is in ELF linker format and may contain
custom ELF notes. These are binary annotations that can be compiled
into the file. The kernel reveals these details for loaded drivers
(i.e., modules) in:
/sys/module/<name>/notes/
The directory contains files like
/sys/module/xfs/notes/.note.gnu.build-id
with a specific name (.note.xenserver) for our purpose. Such a file contains
in binary encoding a sequence of records, each containing:
- A null-terminated name (string)
- A type (integer)
- A desc (see below)
The format of the description is vendor specific and is used for a null-terminated string holding the version. The name is fixed to “XenServer”. The exact format is described in ELF notes.
A note with the name “XenServer” and a particular type then has the version
as a null-terminated string the desc field. Additional “XenServer” notes
of a different type may be present.
API
XAPI has capabilities to inspect and select multi-version drivers.
The API uses the terminology introduced above:
- A driver is specific to a host.
- A driver has a unique name; however, for API purposes a driver is identified by a UUID (on the CLI) and reference (programmatically).
- A driver has multiple variants; each variant has a version. Programatically, variants are represented as objects (referenced by UUID and a reference) but this is mostly hidden in the CLI for convenience.
- A driver variant is active if it is currently used by the kernel (loaded).
- A driver variant is selected if it will be considered by the kernel (on next boot or when loading on demand).
- Only one variant can be active, and only one variants can be selected.
Inspection and selection of drivers is facilitated by a tool (“drivertool”) that is called by xapi. Hence, XAPI does not by itself manipulate the file system that implements driver selection.
An example interaction with the API through xe:
[root@lcy2-dt110 log]# xe hostdriver-list uuid=c0fe459d-5f8a-3fb1-3fe5-3c602fafecc0 params=all
uuid ( RO) : c0fe459d-5f8a-3fb1-3fe5-3c602fafecc0
name ( RO): cisco-fnic
type ( RO): network
description ( RO): cisco-fnic
info ( RO): cisco-fnic
host-uuid ( RO): 6de288e7-0f82-4563-b071-bcdc083b0ffd
active-variant ( RO): <none>
selected-variant ( RO): <none>
variants ( RO): generic/1.2
variants-dev-status ( RO): generic=beta
variants-uuid ( RO): generic=abf5997b-f2ad-c0ef-b27f-3f8a37bf58a6
variants-hw-present ( RO): Selection of a variant by name (which is unique per driver); this variant would become active after reboot.
[root@lcy2-dt110 log]# xe hostdriver-select variant-name=generic uuid=c0fe459d-5f8a-3fb1-3fe5-3c602fafecc0
[root@lcy2-dt110 log]# xe hostdriver-list uuid=c0fe459d-5f8a-3fb1-3fe5-3c602fafecc0 params=all
uuid ( RO) : c0fe459d-5f8a-3fb1-3fe5-3c602fafecc0
name ( RO): cisco-fnic
type ( RO): network
description ( RO): cisco-fnic
info ( RO): cisco-fnic
host-uuid ( RO): 6de288e7-0f82-4563-b071-bcdc083b0ffd
active-variant ( RO): <none>
selected-variant ( RO): generic
variants ( RO): generic/1.2
variants-dev-status ( RO): generic=beta
variants-uuid ( RO): generic=abf5997b-f2ad-c0ef-b27f-3f8a37bf58a6
variants-hw-present ( RO): The variant can be inspected, too, using it’s UUID.
[root@lcy2-dt110 log]# xe hostdriver-variant-list uuid=abf5997b-f2ad-c0ef-b27f-3f8a37bf58a6
uuid ( RO) : abf5997b-f2ad-c0ef-b27f-3f8a37bf58a6
name ( RO): generic
version ( RO): 1.2
status ( RO): beta
active ( RO): false
selected ( RO): true
driver-uuid ( RO): c0fe459d-5f8a-3fb1-3fe5-3c602fafecc0
driver-name ( RO): cisco-fnic
host-uuid ( RO): 6de288e7-0f82-4563-b071-bcdc083b0ffd
hw-present ( RO): falseClass Host_driver
Class Host_driver represents an instance of a multi-version driver on
a host. It references Driver_variant objects for the details of the
available and active variants. A variant has a version.
Fields
All fields are read-only and can’t be set directly. Be aware that names in the CLI and the API may differ.
host: reference to the host where the driver is installed.name: string; name of the driver without “.ko” extension.variants: string set; set of variants available on the host for this driver. The name of each variant of a driver is unique and used in the CLI for selecting it.selected_varinat: variant, possibly empty. Variant that is selected, i.e. the variant of the driver that will be considered by the kernel when loading the driver the next time. May be null when none is selected.active_variant: variant, possibly empty. Variant that is currently loaded by the kernel.type,info,description: strings providing background information.
The CLI uses hostdriver and a dash instead of an underscore. The CLI
also offers convenience fields. Whenever selected and
active variant are not the same, a reboot is required to activate the
selected driver/variant combination.
(We are not using host-driver in the CLI to avoid the impression that
this is part of a host object.)
Methods
All method invocations require
Pool_Operatorrights. “The Pool Operator role manages host- and pool-wide resources, including setting up storage, creating resource pools and managing patches, high availability (HA) and workload balancing (WLB)”select (self, variant); selectvariantof driverself. Selecting the variant (a reference) of an existing driver.deselect(self): this driver can’t be loaded next time the kernel is looking for a driver. This is a potentially dangerous operation, so it’s protected in the CLI with a--forceflag.rescan (host): scan the host and update its driver information. Called on toolstack restart and may be invoked from the CLI for development.
Class Driver_variant
An object of this class represents a variant of a driver on a host, i.e., it is specific to both.
name: unique namedriver: what host driver this belongs toversion: string; a driver variant has a versionstatus: string: development status, like “beta”hardware_present: boolean, true if the host has the hardware installed supported by this driver
The only method available is select(self) to select a variant. It has
the same effect as the select method on the Host_driver class.
The CLI comes with corresponding xe hostdriver-variant-* commands to
list and select a variant.
[root@lcy2-dt110 log]# xe hostdriver-variant-list uuid=abf5997b-f2ad-c0ef-b27f-3f8a37bf58a6
uuid ( RO) : abf5997b-f2ad-c0ef-b27f-3f8a37bf58a6
name ( RO): generic
version ( RO): 1.2
status ( RO): beta
active ( RO): false
selected ( RO): true
driver-uuid ( RO): c0fe459d-5f8a-3fb1-3fe5-3c602fafecc0
driver-name ( RO): cisco-fnic
host-uuid ( RO): 6de288e7-0f82-4563-b071-bcdc083b0ffd
hw-present ( RO): falseDatabase
Each Host_driver and Driver_variant object is represented in the
database and data is persisted over reboots. This means this data will
be part of data collected in a xen-bugtool invocation.
Scan and Rescan
On XAPI start-up, XAPI updates the Host_driver objects belonging to the
host to reflect the actual situation. This can be initiated from the
CLI, too, mostly for development.
NUMA
NUMA in a nutshell
Systems that contain more than one CPU socket are typically built on a Non-Uniform Memory Architecture (NUMA) 12. In a NUMA system each node has fast, lower latency access to local memory.

In the diagram 3 above we have 4 NUMA nodes:
- 2 of those are due to 2 separate physical packages (sockets)
- a further 2 is due to Sub-NUMA-Clustering (aka Nodes Per Socket for AMD) where the L3 cache is split
The L3 cache is shared among multiple cores, but cores 0-5 have lower latency access to one part of it, than cores 6-11, and this is also reflected by splitting memory addresses into 4 31GiB ranges in total.
In the diagram the closer the memory is to the core, the lower the access latency:
- per-core caches: L1, L2
- per-package shared cache: L3 (local part), L3 (remote part)
- local NUMA node (to a group of cores, e.g.
L#0 P#0), node 0 - remote NUMA node in same package (
L#1 P#2), node 1 - remote NUMA node in other packages (
L#2 P#1and ‘L#3P#3’), node 2 and 3
The NUMA distance matrix
Accessing remote NUMA node in the other package has to go through a shared interconnect, which has lower bandwidth than the direct connections, and also a bottleneck if both cores have to access remote memory: the bandwidth for a single core is effectively at most half.
This is reflected in the NUMA distance/latency matrix. The units are arbitrary, and by convention access latency to the local NUMA node is given distance ‘10’.
Relative latency matrix by logical indexes:
| index | 0 | 2 | 1 | 3 |
|---|---|---|---|---|
| 0 | 10 | 21 | 11 | 21 |
| 2 | 21 | 10 | 21 | 11 |
| 1 | 11 | 21 | 10 | 21 |
| 3 | 21 | 11 | 21 | 10 |
This follows the latencies described previously:
- fast access to local NUMA node memory (by definition), node 0, cost 10
- slightly slower access latency to the other NUMA node in same package, node 1, cost 11
- twice as slow access latency to remote NUMA memory in the other physical package (socket): nodes 2 and 3, cost 21
There is also I/O NUMA where a cost is similarly associated to where a PCIe is plugged in, but exploring that is future work (it requires exposing NUMA topology to the Dom0 kernel to benefit from it), and for simplicity the diagram above does not show it.
Advantages of NUMA
NUMA does have advantages though: if each node accesses only its local memory, then each node can independently achieve maximum throughput.
For best performance, we should:
- minimize the amount of interconnect bandwidth we are using
- run code that accesses memory allocated on the closest NUMA node
- maximize the number of NUMA nodes that we use in the system as a whole
If a VM’s memory and vCPUs can entirely fit within a single NUMA node then we should tell Xen to prefer to allocate memory from and run the vCPUs on a single NUMA node.
Xen vCPU soft-affinity
The Xen scheduler supports 2 kinds of constraints:
- hard pinning: a vCPU may only run on the specified set of pCPUs and nowhere else
- soft pinning: a vCPU is preferably run on the specified set of pCPUs, but if they are all busy then it may run elsewhere
Hard pinning can be used to partition the system. But, it can potentially leave part of the system idle while another part is bottlenecked by many vCPUs competing for the same limited set of pCPUs.
Xen does not migrate workloads between NUMA nodes on its own (the Linux kernel can). Although, it is possible to achieve a similar effect with explicit migration. However, migration introduces additional delays and is best avoided for entire VMs.
Therefore, soft pinning is preferred: Running on a potentially suboptimal pCPU that uses remote memory could still be better than not running it at all until a pCPU is free to run it.
Xen will also allocate memory for the VM according to the vCPU (soft) pinning: If the vCPUs are pinned to NUMA nodes A and B, Xen allocates memory from NUMA nodes A and B in a round-robin way, resulting in interleaving.
Current default: No vCPU pinning
By default, when no vCPU pinning is used, Xen interleaves memory from all NUMA nodes. This averages the memory performance, but individual tasks’ performance may be significantly higher or lower depending on which NUMA node the application may have “landed” on. As a result, restarting processes will speed them up or slow them down as address space randomization picks different memory regions inside a VM.
This uses the memory bandwidth of all memory controllers and distributes the load across all nodes. However, the memory latency is higher as the NUMA interconnects are used for most memory accesses and vCPU synchronization within the Domains.
Note that this is not the worst case: the worst case would be for memory to be allocated on one NUMA node, but the vCPU always running on the furthest away NUMA node.
Best effort NUMA-aware memory allocation for VMs
Summary
The best-effort mode attempts to fit Domains into NUMA nodes and to balance memory usage. It soft-pins Domains on the NUMA node with the most available memory when adding the Domain. Memory is currently allocated when booting the VM (or while constructing the resuming VM).
Parallel boot issue: Memory is not pre-allocated on creation, but allocated during boot. The result is that parallel VM creation and boot can exhaust the memory of NUMA nodes.
Goals
By default, Xen stripes the VM’s memory across all NUMA nodes of the host, which means that every VM has to go through all the interconnects. The goal here is to find a better allocation than the default, not necessarily an optimal allocation. An optimal allocation would require knowing what VMs you would start/create in the future, and planning across hosts. This allows the host to use all NUMA nodes to take advantage of the full memory bandwidth available on the pool hosts.
Overall, we want to balance the VMs across NUMA nodes, such that we use all NUMA nodes to take advantage of the maximum memory bandwidth available on the system. For now this proposed balancing will be done only by balancing memory usage: always heuristically allocating VMs on the NUMA node that has the most available memory. For now, this allocation has a race condition: This happens when multiple VMs are booted in parallel, because we don’t wait until Xen has constructed the domain for each one (that’d serialize domain construction, which is currently parallel). This may be improved in the future by having an API to query Xen where it has allocated the memory, and to explicitly ask it to place memory on a given NUMA node (instead of best_effort).
If a VM doesn’t fit into a single node then it is not so clear what the best approach is. One criteria to consider is minimizing the NUMA distance between the nodes chosen for the VM. Large NUMA systems may not be fully connected in a mesh requiring multiple hops to each a node, or even have asymmetric links, or links with different bandwidth. The specific NUMA topology is provided by the ACPI SLIT table as the matrix of distances between nodes. It is possible that 3 NUMA nodes have a smaller average/maximum distance than 2, so we need to consider all possibilities.
For N nodes there would be 2^N possibilities, so [Topology.NUMA.candidates] limits the number of choices to 65520+N (full set of 2^N possibilities for 16 NUMA nodes, and a reduced set of choices for larger systems).
Implementation
[Topology.NUMA.candidates] is a sorted sequence of node sets, in ascending order of maximum/average distances. Once we’ve eliminated the candidates not suitable for this VM (that do not have enough total memory/pCPUs) we are left with a monotonically increasing sequence of nodes. There are still multiple possibilities with same average distance. This is where we consider our second criteria - balancing - and pick the node with most available free memory.
Once a suitable set of NUMA nodes are picked we compute the CPU soft affinity as the union of the CPUs from all these NUMA nodes. If we didn’t find a solution then we let Xen use its default allocation.
The “distances” between NUMA nodes may not all be equal, e.g. some nodes may have shorter links to some remote NUMA nodes, while others may have to go through multiple hops to reach it. See page 13 in 4 for a diagram of an AMD Opteron 6272 system.
Limitations and tradeoffs
- Booting multiple VMs in parallel will result in potentially allocating both on the same NUMA node (race condition)
- When we’re about to run out of host memory we’ll fall back to striping memory again, but the soft affinity mask won’t reflect that (this needs an API to query Xen on where it has actually placed the VM, so we can fix up the mask accordingly)
- XAPI is not aware of NUMA balancing across a pool. Xenopsd chooses NUMA nodes purely based on amount of free memory on the NUMA nodes of the host, even if a better NUMA placement could be found on another host
- Very large (>16 NUMA nodes) systems may only explore a limited number of choices (fit into a single node vs fallback to full interleaving)
- The exact VM placement is not yet controllable
- Microbenchmarks with a single VM on a host show both performance improvements and regressions on memory bandwidth usage: previously a single VM may have been able to take advantage of the bandwidth of both NUMA nodes if it happened to allocate memory from the right places, whereas now it’ll be forced to use just a single node. As soon as you have more than 1 VM that is busy on a system enabling NUMA balancing should almost always be an improvement though.
- It is not supported to combine hard vCPU masks with soft affinity: if hard affinities are used, then no NUMA scheduling is done by the toolstack, and we obey exactly what the user has asked for with hard affinities. This shouldn’t affect other VMs since the memory used by hard-pinned VMs will still be reflected in overall less memory available on individual NUMA nodes.
- Corner case: the ACPI standard allows certain NUMA nodes to be unreachable (distance
0xFF=-1in the Xen bindings). This is not supported and will cause an exception to be raised. If this is an issue in practice the NUMA matrix could be pre-filtered to contain only reachable nodes. NUMA nodes with 0 CPUs are accepted (it can result from hard affinity pinning) - NUMA balancing is not considered during HA planning
- Dom0 is a single VM that needs to communicate with all other VMs, so NUMA balancing is not applied to it (we’d need to expose NUMA topology to the Dom0 kernel, so it can better allocate processes)
- IO NUMA is out of scope for now
XAPI datamodel design
- New API field:
Host.numa_affinity_policy. - Choices:
default_policy,any,best_effort. - On upgrade the field is set to
default_policy - Changes in the field only affect newly (re)booted VMs, for changes to take effect on existing VMs a host evacuation or reboot is needed
There may be more choices in the future (e.g. strict, which requires both Xen and toolstack changes).
Meaning of the policy:
any: the Xen default where it allocated memory by striping across NUMA nodesbest_effort: the algorithm described in this document, where soft pinning is used to achieve better balancing and lower latencydefault_policy: when the admin hasn’t expressed a preferenceCurrently,
default_policyis treated asany, but the admin can change it, and then the system will remember that change across upgrades. If we didn’t have adefault_policythen changing the “default” policy on an upgrade would be tricky: we either risk overriding an explicit choice of the admin, or existing installs cannot take advantage of the improved performance frombest_effortFuture XAPI versions may change
default_policyto meanbest_effort. Admins can still override it toanyif they wish on a host by host basis.
It is not expected that users would have to change best_effort, unless they run very specific workloads, so a pool level control is not provided at this moment.
There is also no separate feature flag: this host flag acts as a feature flag that can be set through the API without restarting the toolstack. Although obviously only new VMs will benefit.
Debugging the allocator is done by running xl vcpu-list and investigating the soft pinning masks, and by analyzing xensource.log.
Xenopsd implementation
See the documentation in [softaffinity.mli] and [topology.mli].
- [Softaffinity.plan] returns a [CPUSet] given a host’s NUMA allocation state and a VM’s NUMA allocation request.
- [Topology.CPUSet] provides helpers for operating on a set of CPU indexes.
- [Topology.NUMAResource] is a [CPUSet] and the free memory available on a NUMA node.
- [Topology.NUMARequest] is a request for a given number of vCPUs and memory in bytes.
- [Topology.NUMA] represents a host’s NUMA allocation state.
- [Topology.NUMA.candidates] are groups of nodes orderd by minimum average distance. The sequence is limited to [N+65520], where [N] is the number of NUMA nodes. This avoids exponential state space explosion on very large systems (>16 NUMA nodes).
- [Topology.NUMA.choose] will choose one NUMA node deterministically, while trying to keep overall NUMA node usage balanced.
- [Domain.numa_placement] builds a [NUMARequest] and uses the above [Topology] and [Softaffinity] functions to compute and apply a plan.
We used to have a xenopsd.conf configuration option to enable NUMA placement, for backwards compatibility this is still supported, but only if the admin hasn’t set an explicit policy on the Host.
It is best to remove the experimental xenopsd.conf entry though, a future version may completely drop it.
Tests are in [test_topology.ml] which checks balancing properties and whether the plan has improved best/worst/average-case access times in a simulated test based on 2 predefined NUMA distance matrixes (one from Intel and one from an AMD system).
Future work
- Enable ‘best_effort’ mode by default once more testing has been done
- Add an API to query Xen for the NUMA node memory placement (where it has actually allocated the VM’s memory).
Currently, only the
xl debug-keysinterface exists which is not supported in production as it can result in killing the host via the watchdog, and is not a proper API, but a textual debug output with no stability guarantees. - More host policies, e.g.
strict. Requires the XAPI pool scheduler to be NUMA aware and consider it as part of choosing hosts. - VM level policy that can set a NUMA affinity index, mapped to a NUMA node modulo NUMA nodes available on the system (this is needed so that after migration we don’t end up trying to allocate vCPUs to a non-existent NUMA node)
- VM level anti-affinity rules for NUMA placement (can be achieved by setting unique NUMA affinity indexes)
created with
lstopo-no-graphics --no-io --of svg --vert=L3 >hwloc.svgon a bare metal Linux ↩︎Lepers, Baptiste. “Improving performance on NUMA systems.” PhD diss., Université de Grenoble, 2014. ↩︎
Snapshots
Snapshots represent the state of a VM, or a disk (VDI) at a point in time. They can be used for:
- backups (hourly, daily, weekly etc)
- experiments (take snapshot, try something, revert back again)
- golden images (install OS, get it just right, clone it 1000s of times)
Read more about the Snapshot APIs.
Disk snapshots
Disks are represented in the XenAPI as VDI objects. Disk snapshots are represented
as VDI objects with the flag is_a_snapshot set to true. Snapshots are always
considered read-only, and should only be used for backup or cloning into new
disks. Disk snapshots have a lifetime independent of the disk they are a snapshot
of i.e. if someone deletes the original disk, the snapshots remain. This contrasts
with some storage arrays in which snapshots are “second class” objects which are
automatically deleted when the original disk is deleted.
Disks are implemented in Xapi via “Storage Manager” (SM) plugins. The SM plugins conform to an api (the SMAPI) which has operations including
- vdi_create: make a fresh disk, full of zeroes
- vdi_snapshot: create a snapshot of a disk
File-based vhd implementation
The existing “EXT” and “NFS” file-based Xapi SM plugins store disk data in trees of .vhd files as in the following diagram:
From the XenAPI point of view, we have one current VDI and a set of snapshots, each taken at a different point in time. These VDIs correspond to leaf vhds in a tree stored on disk, where the non-leaf nodes contain all the shared blocks.
The vhd files are always thinly-provisioned which means they only allocate new blocks on an as-needed basis. The snapshot leaf vhd files only contain vhd metadata and therefore are very small (a few KiB). The parent nodes containing the shared blocks only contain the shared blocks. The current leaf initially contains only the vhd metadata and therefore is very small (a few KiB) and will only grow when the VM writes blocks.
File-based vhd implementations are a good choice if a “gold image” snapshot is going to be cloned lots of times.
Block-based vhd implementation
The existing “LVM”, “LVMoISCSI” and “LVMoHBA” block-based Xapi SM plugins store disk data in trees of .vhd files contained within LVM logical volumes:
Non-snapshot VDIs are always stored full size (a.k.a. thickly-provisioned). When parent nodes are created they are automatically shrunk to the minimum size needed to store the shared blocks. The LVs corresponding with snapshot VDIs only contain vhd metadata and by default consume 8MiB. Note: this is different to VDI.clones which are stored full size.
Block-based vhd implementations are not a good choice if a “gold image” snapshot is going to be cloned lots of times, since each clone will be stored full size.
Hypothetical LUN implementation
A hypothetical Xapi SM plugin could use LUNs on an iSCSI storage array as VDIs, and the array’s custom control interface to implement the “snapshot” operation:
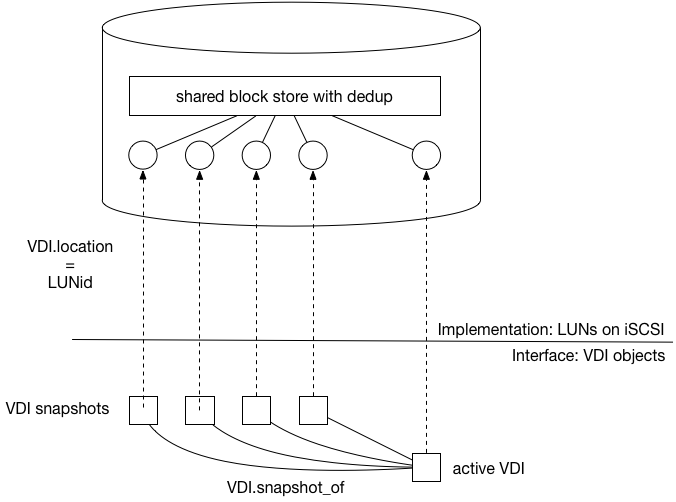
From the XenAPI point of view, we have one current VDI and a set of snapshots, each taken at a different point in time. These VDIs correspond to LUNs on the same iSCSI target, and internally within the target these LUNs are comprised of blocks from a large shared copy-on-write pool with support for dedup.
Reverting disk snapshots
There is no current way to revert in-place a disk to a snapshot, but it is possible to create a writable disk by “cloning” a snapshot.
VM snapshots
Let’s say we have a VM, “VM1” that has 2 disks. Concentrating only on the VM, VBDs and VDIs, we have the following structure:
When we take a snapshot, we first ask the storage backends to snapshot all of the VDIs associated with the VM, producing new VDI objects. Then we copy all of the metadata, producing a new ‘snapshot’ VM object, complete with its own VBDs copied from the original, but now pointing at the snapshot VDIs. We also copy the VIFs and VGPUs but for now we will ignore those.
This process leads to a set of objects that look like this:
We have fields that help navigate the new objects: VM.snapshot_of,
and VDI.snapshot_of. These, like you would expect, point to the
relevant other objects.
Deleting VM snapshots
When a snapshot is deleted Xapi calls the SM API vdi_delete. The Xapi SM
plugins which use vhd format data do not reclaim space immediately; instead
they mark the corresponding vhd leaf node as “hidden” and, at some point later,
run a garbage collector process.
The garbage collector will first determine whether a “coalesce” should happen i.e. whether any parent nodes have only one child i.e. the “shared” blocks are only “shared” with one other node. In the following example the snapshot delete leaves such a parent node and the coalesce process copies blocks from the redundant parent’s only child into the parent:
Note that if the vhd data is being stored in LVM, then the parent node will have had to be expanded to full size to accommodate the writes. Unfortunately this means the act of reclaiming space actually consumes space itself, which means it is important to never completely run out of space in such an SR.
Once the blocks have been copied, we can now cut one of the parents out of the tree by relinking its children into their grandparent:
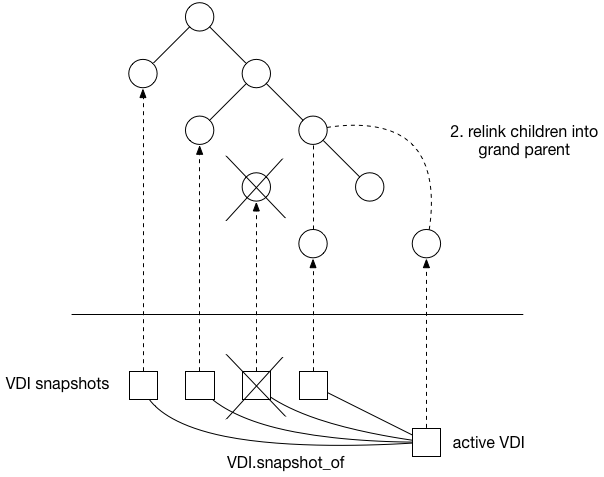
Finally the garbage collector can remove unused vhd files / LVM LVs:
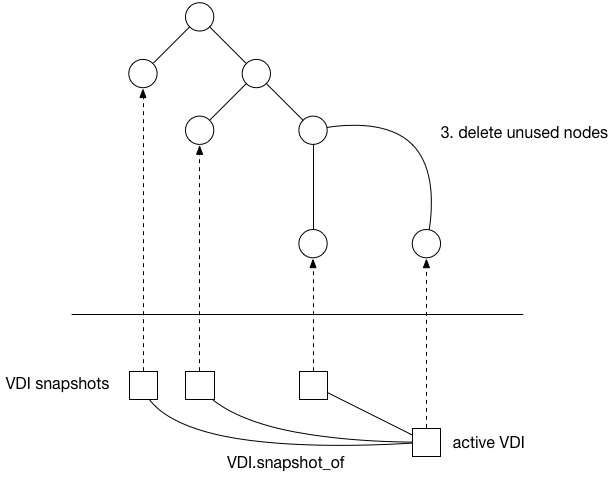
Reverting VM snapshots
The XenAPI call VM.revert overwrites the VM metadata with the snapshot VM
metadata, deletes the current VDIs and replaces them with clones of the
snapshot VDIs. Note there is no “vdi_revert” in the SMAPI.
Revert implementation details
This is the process by which we revert a VM to a snapshot. The first thing to notice is that there is some logic that is called from message_forwarding.ml, which uses some low-level database magic to turn the current VM record into one that looks like the snapshot object. We then go to the rest of the implementation in xapi_vm_snapshot.ml. First, we shut down the VM if it is currently running. Then, we revert all of the VBDs, VIFs and VGPUs. To revert the VBDs, we need to deal with the VDIs underneath them. In order to create space, the first thing we do is delete all of the VDIs currently attached via VBDs to the VM. We then clone the disks from the snapshot. Note that there is no SMAPI operation ‘revert’ currently - we simply clone from the snapshot VDI. It’s important to note that cloning creates a new VDI object: this is not the one we started with gone.
Tracing
Tracing is a powerful tool for observing system behavior across multiple components, making it especially useful for debugging and performance analysis in complex environments.
By integrating OpenTelemetry (a standard that unifies OpenTracing and OpenCensus) and the Zipkin v2 protocol, XAPI enables efficient tracking and visualization of operations across internal and external systems. This facilitates detailed analysis and improves collaboration between teams.
Tracing is commonly used in high-level applications such as web services. As a result, less widely-used or non-web-oriented languages may lack dedicated libraries for distributed tracing (An OCaml implementation has been developed specifically for XenAPI).
How tracing works in XAPI
Spans and Trace Context
- A span is the core unit of a trace, representing a single operation with a defined start and end time.
Spans can contain sub-spans that represent child tasks. This helps identify bottlenecks or areas that
can be parallelized.
- A span can contain several contextual elements such as tags (key-value pairs), events (time-based data), and errors.
- The TraceContext HTTP standard defines how trace IDs and span contexts are propagated across systems, enabling full traceability of operations.
This data enables the creation of relationships between tasks and supports visualizations such as architecture diagrams or execution flows. These help in identifying root causes of issues and bottlenecks, and also assist newcomers in onboarding to the project.
Configuration
To enable tracing, you need to create an Observer object in XAPI. This can be done using the xe CLI:
xe observer-create \ name-label=<name> \ enabled=true \ components=xapi,xenopsd \By default, if you don’t specify
enabled=true, the observer will be disabled.To add an HTTP endpoint, make sure the server is up and running, then run:
xe observer-param-set uuid=<OBSERVER_UUID> endpoints=bugtool,http://<jaeger-ip>:9411/api/v2/spansIf you specify an invalid or unreachable HTTP endpoint, the configuration will fail.
components: Specify which internal components (e.g., xapi, xenopsd) should be traced. Additional components are expected to be supported in future releases. An experimental smapi component is also available and requires additional configuration (explained below).
endpoints: The observer can collect traces locally in /var/log/dt or forward them to external visualization tools such as Jaeger. Currently, only HTTP/S endpoints are supported, and they require additional configuration steps (see next section).
To disable tracing you just need to set enabled to false:
xe observer-param-set uuid=<OBSERVER_UUID> enabled=false
Enabling smapi component
- smapi component is currently considered experimental and is filtered by default. To enable it, you must
explicitly configure the following in xapi.conf:This tells XAPI that no components are considered experimental, thereby allowing smapi to be traced. A modification to xapi.conf requires a restart of the XAPI toolstack.
observer-experimental-components=""
Enabling HTTP/S endpoints
- By default HTTP and HTTPS endpoints are disabled. To enable them, add the following lines to xapi.conf:As with enabling smapi component, modifying xapi.conf requires a restart of the XAPI toolstack. Note: HTTPS endpoint support is available but not tested and may not work.
observer-endpoint-http-enabled=true observer-endpoint-https-enabled=true
Sending local trace to endpoint
By default, traces are generated locally in the /var/log/dt directory. You can copy or forward
these traces to another location or endpoint using the xs-trace tool. For example, if you have
a Jaeger server running locally, you can copy a trace to an endpoint by running:
xs-trace cp /var/log/dt/ http://127.0.0.1:9411/api/v2/spansYou will then be able to visualize the traces in Jaeger.
The xs-trace tool also supports trace files in .ndjson and compressed .zst formats, so
you can copy or forward these files directly as well.
Tagging Trace Sessions for Easier Search
Specific attributes
To make trace logs easier to locate and analyze, it can be helpful to add custom attributes around the execution of specific commands. For example:
# xe observer-param-set uuid=<OBSERVER_UUID> attributes:custom.random=1234
# xe vm-start ...
# xe observer-param-clear uuid=<OBSERVER_UUID> param-name=attributes param-key=custom.randomThis technique adds a temporary attribute, custom.random=1234, which will appear in the generated trace spans, making it easier to search for specific activity in trace visualisation tools. It may also be possible to achieve similar tagging using baggage parameters directly in individual xe commands, but this approach is currently undocumented.
Baggage
Baggage, contextual information that resides alongside the context, is supported. This means you can run the following command:
BAGGAGE="mybaggage=apples" xe vm-listYou will be able to search for tags mybaggage=apples.
Traceparent
Another way to assist in trace searching is to use the TRACEPARENT HTTP header. It is an HTTP header field that
identifies the incoming request. It has a specific format
and it is supported by XAPI. Once generated you can run command as:
TRACEPARENT="00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01" xe vm-listAnd you will be able to look for trace 4bf92f3577b34da6a3ce929d0e0e4736.
Links
vGPU
XenServer has supported passthrough for GPU devices since XenServer 6.0. Since the advent of NVIDIA’s vGPU-capable GRID K1/K2 cards it has been possible to carve up a GPU into smaller pieces yielding a more scalable solution to boosting graphics performance within virtual machines.
The K1 has four GK104 GPUs and the K2 two GK107 GPUs. Each of these will be exposed through Xapi so a host with a single K1 card will have access to four independent PGPUs.
Each of the GPUs can then be subdivided into vGPUs. For each type of PGPU, there are a few options of vGPU type which consume different amounts of the PGPU. For example, K1 and K2 cards can currently be configured in the following ways:
Note, this diagram is not to scale, the PGPU resource required by each vGPU type is as follows:
| vGPU type | PGPU kind | vGPUs / PGPU |
|---|---|---|
| k100 | GK104 | 8 |
| k140Q | GK104 | 4 |
| k200 | GK107 | 8 |
| k240Q | GK107 | 4 |
| k260Q | GK107 | 2 |
Currently each physical GPU (PGPU) only supports homogeneous vGPU configurations but different configurations are supported on different PGPUs across a single K1/K2 card. This means that, for example, a host with a K1 card can run 64 VMs with k100 vGPUs (8 per PGPU).
XenServer’s vGPU architecture
A new display type has been added to the device model:
@@ -4519,6 +4522,7 @@ static const QEMUOption qemu_options[] =
/* Xen tree options: */
{ "std-vga", 0, QEMU_OPTION_std_vga },
+ { "vgpu", 0, QEMU_OPTION_vgpu },
{ "videoram", HAS_ARG, QEMU_OPTION_videoram },
{ "d", HAS_ARG, QEMU_OPTION_domid }, /* deprecated; for xend compatibility */
{ "domid", HAS_ARG, QEMU_OPTION_domid },
With this in place, qemu can now be started using a new option that will
enable it to communicate with a new display emulator, vgpu to expose the
graphics device to the guest. The vgpu binary is responsible for handling the
VGX-capable GPU and, once it has been successfully passed through, the in-guest
drivers can be installed in the same way as when it detects new hardware.
The diagram below shows the relevant parts of the architecture for this project.
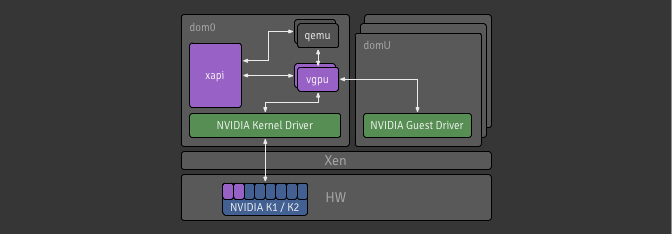
Relevant code
- In Xenopsd: Xenops_server_xen is where Xenopsd gets the vGPU information from the values passed from Xapi;
- In Xenopsd: Device.__start is where the
vgpuprocess is started, if necessary, before Qemu.
Xapi’s API and data model
A lot of work has gone into the toolstack to handle the creation and management
of VMs with vGPUs. We revised our data model, introducing a semantic link
between VGPU and PGPU objects to help with utilisation tracking; we
maintained the GPU_group concept as a pool-wide abstraction of PGPUs
available for VMs; and we added VGPU_types which are configurations for
VGPU objects.
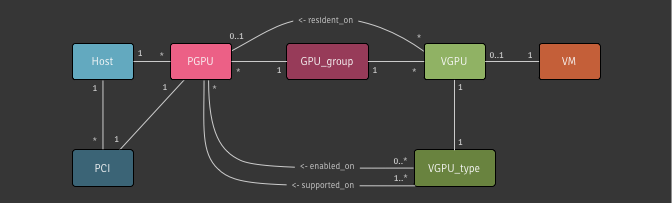
Aside: The VGPU type in Xapi’s data model predates this feature and was synonymous with GPU-passthrough. A VGPU is simply a display device assigned to a VM which may be a vGPU (this feature) or a whole GPU (a VGPU of type passthrough).
VGPU_types can be enabled/disabled on a per-PGPU basis allowing for
reservation of particular PGPUs for certain workloads. VGPUs are allocated on
PGPUs within their GPU group in either a depth-first or breadth-first
manner, which is configurable on a per-group basis.
VGPU_types are created by xapi at startup depending on the available
hardware and config files present in dom0. They exist in the pool database, and
a primary key is used to avoid duplication. In XenServer 6.x the tuple of
(vendor_name, model_name) was used as the primary key, however this was not
ideal as these values are subject to change. XenServer 7.0 switched to a
new primary key
generated from static metadata, falling back to the old method for backwards
compatibility.
A VGPU_type will be garbage collected when there is no VGPU of that type
and there is no hardware which supports that type. On VM import, all VGPUs and
VGPU_types will be created if necessary - if this results in the creation of a
new VGPU_type then the VM will not be usable until the required hardware and
drivers are installed.
Relevant code
- In Xapi: Xapi_vgpu_type contains the type definitions and parsing logic for vGPUs;
- In Xapi: Xapi_pgpu_helpers defines the functions used to allocate vGPUs on PGPUs.
Xapi <-> Xenopsd interface
In XenServer 6.x, all VGPU config was added to the VM’s platform field at
startup, and this information was used by xenopsd to start the display emulator.
See the relevant code in ocaml/xapi/vgpuops.ml.
In XenServer 7.0, to facilitate support of VGPU on Intel hardware in parallel with the existing NVIDIA support, VGPUs were made first-class objects in the xapi-xenopsd interface. The interface is described in the design document on the GPU support evolution.
VM startup
On the pool master:
- Assuming no WLB, all VM.start tasks pass through Xapi_vm_helpers.choose_host_for_vm_no_wlb. If the VM has a vGPU, the list of all hosts in the pool is split into a list of lists, where the first list is the most optimal in terms of the GPU group’s allocation mode and the PGPU availability on each host.
- Each list of hosts in turn is passed to Xapi_vm_placement.select_host, which checks storage, network and memory availability, until a suitable host is found.
- Once a host has been chosen, allocate_vm_to_host will set the
VM.scheduled_to_be_resident_onandVGPU.scheduled_to_be_resident_onfields.
The task is then ready to be forwarded to the host on which the VM will start:
- If the VM has a VGPU, the startup task is wrapped in Xapi_gpumon.with_gpumon_stopped. This makes sure that the NVIDIA driver is not in use so can be loaded or unloaded from physical GPUs as required.
- The VM metadata, including VGPU metadata, is passed to xenopsd. The creation of the VGPU metadata is done by vgpus_of_vm. Note that at this point passthrough VGPUs are represented by the PCI device type, and metadata is generated by pcis_of_vm.
- As part of starting up the VM, xenopsd should report a VGPU event or a
PCI event, which xapi will use to indicate that the xapi VGPU object can
be marked as
currently_attached.
Usage
To create a VGPU of a given type you can use vgpu-create:
$ xe vgpu-create vm-uuid=... gpu-group-uuid=... vgpu-type-uuid=...To see a list of VGPU types available for use on your XenServer, run the
following command. Note: these will only be populated if you have installed the
relevant NVIDIA RPMs and if there is hardware installed on that host supported
each type. Using params=all will display more information such as the maximum
number of heads supported by that VGPU type and which PGPUs have this type
enabled and supported.
$ xe vgpu-type-list [params=all]To access the new and relevant parameters on a PGPU (i.e.
supported_VGPU_types, enabled_VGPU_types, resident_VGPUs) you can use
pgpu-param-get with param-name=supported-vgpu-types
param-name=enabled-vgpu-types and param-name=resident-vgpus respectively.
Or, alternatively, you can use the following command to list all the parameters
for the PGPU. You can get the types supported or enabled for a given PGPU:
$ xe pgpu-list uuid=... params=allXapi Storage Migration
The Xapi Storage Migration (XSM) also known as “Storage Motion” allows
- a running VM to be migrated within a pool, between different hosts and different storage simultaneously;
- a running VM to be migrated to another pool;
- a disk attached to a running VM to be moved to another SR.
The following diagram shows how XSM works at a high level:
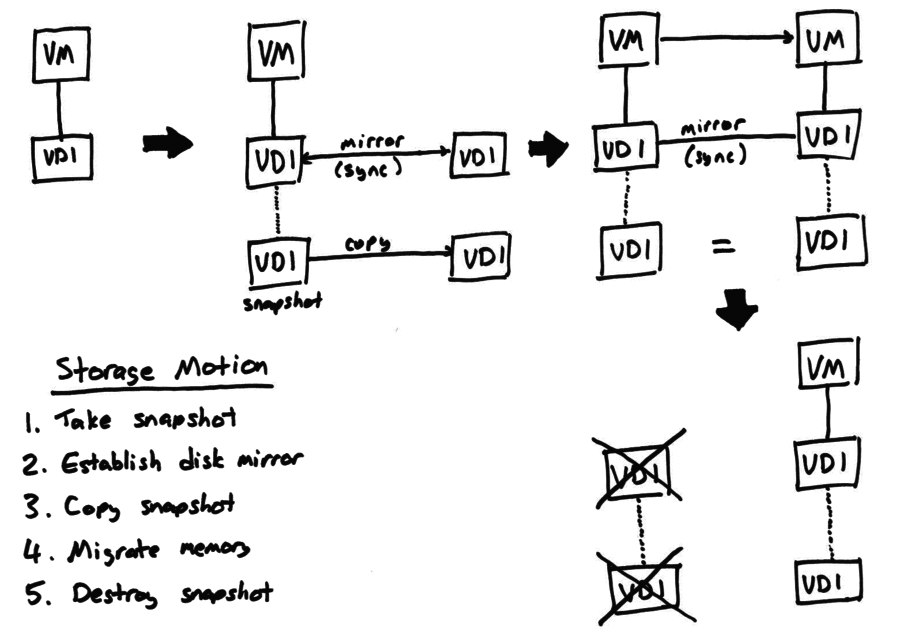
The slowest part of a storage migration is migrating the storage, since virtual
disks can be very large. Xapi starts by taking a snapshot and copying that to
the destination as a background task. Before the datapath connecting the VM
to the disk is re-established, xapi tells tapdisk to start mirroring all
writes to a remote tapdisk over NBD. From this point on all VM disk writes
are written to both the old and the new disk.
When the background snapshot copy is complete, xapi can migrate the VM memory
across. Once the VM memory image has been received, the destination VM is
complete and the original can be safely destroyed.