Disaster Recovery
The HA feature will restart VMs after hosts have failed, but what happens if a whole site (e.g. datacenter) is lost? A disaster recovery configuration is shown in the following diagram:
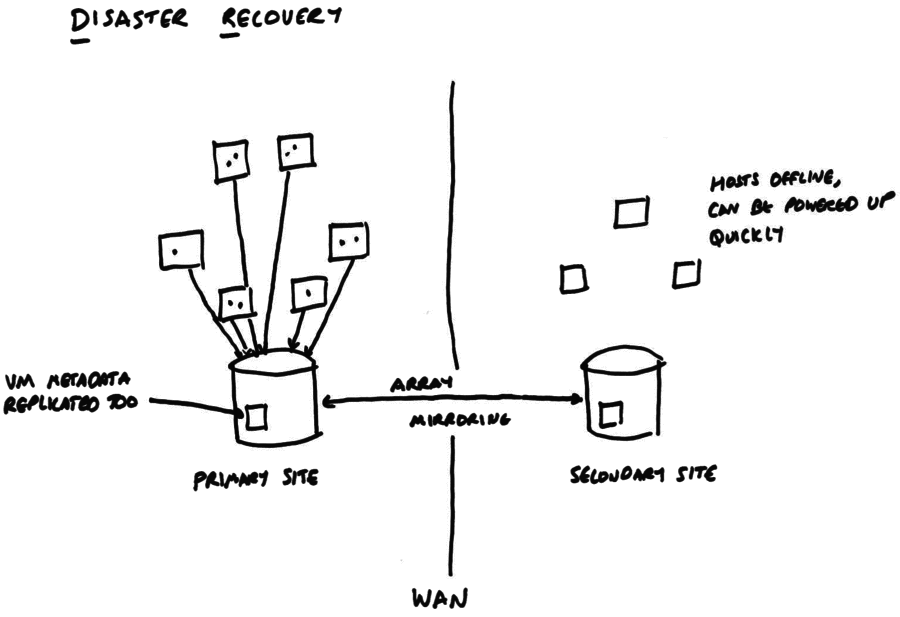
We rely on the storage array’s built-in mirroring to replicate (synchronously or asynchronously: the admin’s choice) between the primary and the secondary site. When DR is enabled the VM disk data and VM metadata are written to the storage server and mirrored. The secondary site contains the other side of the data mirror and a set of hosts, which may be powered off.
In normal operation, the DR feature allows a “dry-run” recovery where a host on the secondary site checks that it can indeed see all the VM disk data and metadata. This should be done regularly, so that admins are familiar with the process.
After a disaster, the admin breaks the mirror on the secondary site and triggers a remote power-on of the offline hosts (either using an out-of-band tool or the built-in host power-on feature of xapi). The pool master on the secondary site can connect to the storage and extract all the VM metadata. Finally the VMs can all be restarted.
When the primary site is fully recovered, the mirror can be re-synchronised and the VMs can be moved back.